[LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 1
지면 상 또 작성 시간 상 이전 글들에서 작성한 부분은 과감하게 생략하고 넘어가도록 하겠다. 본 블로그의 아래 시리즈들을 참고하면 된다. 2020.12.03 - [Backend MLOps/개인 환경 구축 기록] - [ 자취
davi06000.tistory.com
2편이다. 컨테이너를 띄우기까지 시행착오가 많았어서 시행착오와 함께 기록해 두려고 한다.
// - 문제상황:
Ollama 공식 이미지를 이용해서 run한 컨테이너는 어떤 커멘드로 실행해도 파드가 죽어버리는 현상이 있었다.
// - 원인:

공식 이미지의 뚜껑을 따보면 위와 같다.
원래 이미지는 "/bin/ollama serve" 명령어를 이용해서 앱을 서빙하여 컨테이너를 유지하는 것으로 보인다.
저렇게 서빙을 시작하고 나면 다른 조작을 인터렉티브하게 할 수 없는 상태가 되기 때문에
다음 명령어를 실행하려면 반드시 서빙 부분을 백그라운드에서 실행해줘야 한다.
// - 시행착오:
그러면 ollama라는 명령어를 사용하기 위해서
가장 먼저 앱을 백그라운드에서 서빙하게 만들고
그 다음 모델을 불러오는 코드를 실행해서 사용할 수 있는 상태를 만드는 것이 가장 쉬운 방법일 것 같다.

원래 이미지대로 컨테이너를 띄우고
도커 로그를 보니 이미지의 CMD 에 따라 앱이 잘 실행된 것을 알 수 있고

앱이 실행된 후에 컨테이너 내부의 터미널에서 ollama명령어를 쓸 수 있는 것을 알 수있다.
하지만
엔트리포인트를 "/bin/ollama serve & ...." 으로 수정한 뒤에 컨테이너를 실행해 보면
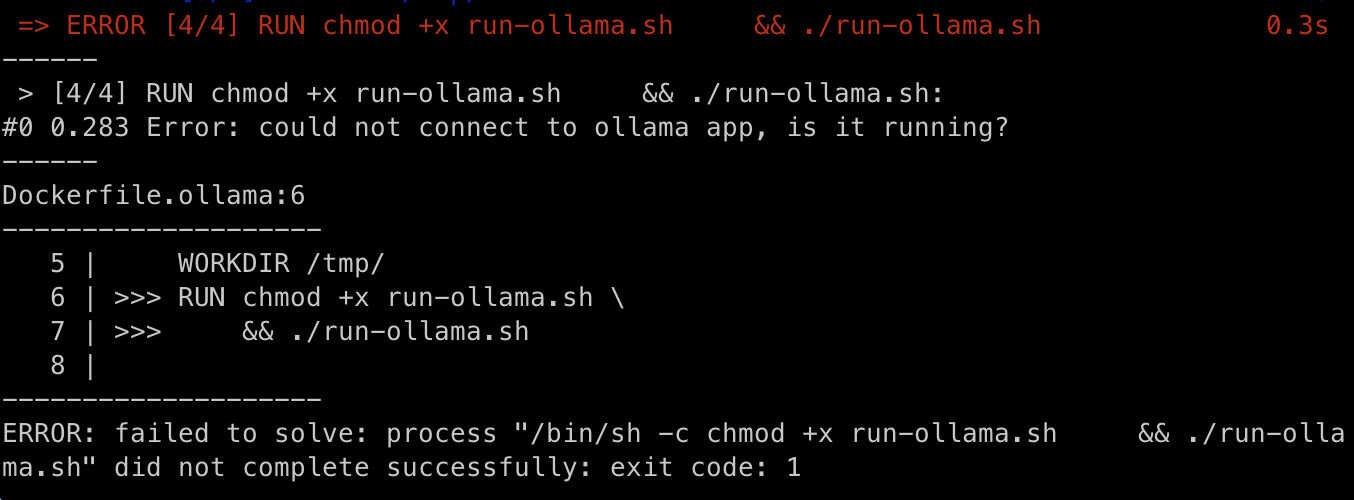
어쩐 일인지 명령어가 실행이 안되고
Error: could not connect to ollama app, is it running?
이라는 에러 메세지가 계속해서 뜬다.
몇가지 가설을 검증한 끝에 알게된 사실은
ollama앱을 실행하고 나서
"ollama" 라는 커멘드를 사용할 수 있는 상태가 되기 까지
약간의 시간이 필요하다는 것이다.
앱이 정상적으로 구동되기까지 아주 잠깐의 시간이 필요해 보인다.
/bin/ollama serve &
while ! ollama
do
sleep 1
done
ollama pull model쿠버네티스 yaml을 작성할때 파드를 생성하는 부분에서
위와 같이 ollama가 정상적으로 동작하는지 아닌지 확인하는 루프를 중간에 넣고
돌려주면 잘 돌아가는 것을 알 수 있었다.
그러면 이 명령어를 기존의 이미지 엔트리포인트에 덮어 쓰고
컨테이너를 실행시키면 우리가 원하는 LLM이 들어있는 ollama가 완성된다.
우선은 파드를 하나 띄우는 것 부터 시작하자.
먼저 라즈베리파이 5에 파드가 뜨길 원하므로
sudo k3s kubectl label node pi5-1 piversion=pi5
sudo k3s kubectl label node pi5-2 piversion=pi5
이렇게 노드에 라벨을 붙여준다.
이 라벨을 이용하여 노드셀렉터를 정할 것이다.
apiVersion: v1
kind: Pod
metadata:
name: ollama-single
namespace: ollama
labels:
app: ollama
spec:
nodeSelector:
piversion: pi5
containers:
- name: ollama
image: ollama/ollama
command: ["/bin/sh", "-c"]
args:
- |
/bin/ollama serve &
while ! ollama
do
sleep 1
done
/bin/ollama pull llama3
ports:
- containerPort: 11434
---
apiVersion: v1
kind: Service
metadata:
name: ollama-service
namespace: ollama
spec:
selector:
app: ollama
ports:
- protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
type: NodePort포트를 하나 열어주고 노드포트를 이용해서 노출시켜주었다.

파드의 로그를 보면 ollama를 한번 실행한 후에 확인이 끝나면 그 다음을 진행하는 것을 볼 수 있다.

로그를 계속 찍어보면 모델이 다운로드 되고 있는 것이 보인다.
생각보다 오래 걸린다. 따라서 큰 모델들 보다는 phi등의 작은 모델을 사용해서
테스트를 진행하는 것이 좋을 것 같다.

다운로드가 끝났다.
sudo k3s kubectl get svc -n ollama이렇게 서비스를 확인해서 노드의 포트가 잘 열려있는지 확인한 후
프롬프트를 보내보면 서버가 꺼졌다고 나온다.
백그라운드에서 앱이 실행중이지만
마지막 포어그라운드 명령어가 완료되었기 때문에
파드가 completed상태가 되었다가 죽고 다시 살아나는 현상이다.
아무래도 포어그라운드에서 한번 더 서빙을 해 줘야 할 것 같다.
/bin/ollama serve &
while ! ollama
do
sleep 1
done
ollama pull model
pkil -f "/bin/ollama serve"
/bin/ollama serve
커멘드 부분을 이렇게 바꿔준다.
마지막 커멘드를 억지로 serve로 만들어주었다.
하지만 이 방법은 잘 안먹히는게 ollama앱을 죽이면 컨테이너도 같이 죽어버리는 현상이 있었다.
쉘이 왜 유지되지 않는지는 알 수 없었지만 이 방법도 사실 엘레강스하지는 않다고 본다.
// - 해결 :
더 좋은 방법이 없을까 고민하다가 아래의 레포를 찾게 되었다.
https://github.com/otwld/ollama-helm/tree/main/templates
ollama-helm/templates at main · otwld/ollama-helm
Helm chart for Ollama on Kubernetes. Contribute to otwld/ollama-helm development by creating an account on GitHub.
github.com
ollama를 배포하는 헬름차트가 있었다.
그리고 이 차트안에는 시작과 함께 모델의 다운로드를 진행하는 부분도 포함되어 있었다.

사전에 정의된 파일에 디폴트 모델이 설정되어 있다면
그 디폴트 모델을 pull하는 구문인데 여기서는 라이프사이클을 이용한다.
컨테이너의 라이프 사이클을 요약하면 컨테이너가 생성되고 죽기까지를 하나의 라이프로 보고
그 라이프를 여러 페이즈로 나누어 관리하는 테크닉을 말한다.
지금 우리가 사용할 라이프사이클은 postStart로
말 그대로 컨테이너가 시작하면 수행할 명령어를 입력하는 과정을 추가하는 것이다.
공식 문서에 따르면 엔트리포인트와는 서로 비동기적으로 동작한다고 하니
인터렉티브 하지 않은 상태로 들어가는 앱 실행과는 별도로 어떤 명령을 추가적으로 할 수 있다고 보여진다.

위와 같이 디플로이먼트를 지정해 주고 서비스도 명시해 주었다.
이렇게 디플로이먼트를 배포한 후에 시간이 조금 지나면

이렇게 대답을 볼 수 있다.

이번엔 pi가 아닌 외부에서 프롬프트를 날려보았다.
역시 잘 동작한다.
알아보기가 매우 힘들기 때문에 랭체인을 이용해 보면
https://api.python.langchain.com/en/latest/llms/langchain_community.llms.ollama.Ollama.html
langchain_community.llms.ollama.Ollama — 🦜🔗 LangChain 0.1.16
api.python.langchain.com
여기를 참고하여

아주 재미있는 농담과 함께 성공을 볼 수 있다.
그런데 아주 작은 농담을 만드는데도 11초가 걸리는 것을 볼 수 있다.
// - 부하분산:
생각보다 오래걸린다.
이번에는 레플리카셋을 늘려서 속도차이를 비교해 보자

phi모델은 어림잡아 2GB 로 치면 이론상 8개의 파드를 띄우는 것이 가능하다.
from langchain_community.llms import Ollama
import asyncio
import time
llm = Ollama(
base_url="http://192.168.0.11:31434",
model="phi",
temperature=0
)
async def async_task():
await llm.ainvoke("Tell me a joke")
async def run_benchmark(num_tasks):
start_time = time.time()
await asyncio.gather(*[async_task() for _ in range(num_tasks)])
end_time = time.time()
elapsed_time = end_time - start_time
return elapsed_time
async def main(num_tasks):
elapsed_time = await run_benchmark(num_tasks)
return elapsed_time
if __name__ == "__main__":
num_tasks = 10
elapsed_time = asyncio.run(main(num_tasks))
print(f"Completed {num_tasks} tasks in {elapsed_time:.2f} seconds")
이렇게 비동기로 밴치마크를 하는 코드를 짜 준다.
파드 1개 에 대해서 실행했을때 결과이다.

이번에는 파드를 8로 늘리고 실험해 보자.

다운로드에 시간이 조금 많이 걸린다.

이제 돌려보면

엥
더 더 느려진 것을 알 수 있다.
라즈베리파이5는 쿼드코어라 노드 하나당 4개의 파드가 할당되었다면 느려질 이유가 없지만
메모리상 그렇지 않을 수 있어서 사용량을 찍어보겠다.


역시 2대의 파이5 중에 하나의 노드에만 파드가 몰려 생겨서 병목이 발생해버렸다.

리소스를 위와 같이 설정해 주어서 파드들이 고르게 생성되도록 했다.

이번엔 양쪽에서 다 리소스를 사용하고있다.

그런데 이번엔 응답없는 수준으로 느리게 돌아간다.
생각을 해보니 ollama가 자체적으로 멀티프로세싱으로 돌아가게 설계되어 있으면
컨테이너 하나당 하나의 코어를 할당하는 것이 성능 저하를 불러올 수 있다.
그래서 이 가설이 맞다면
차라리 하나의 컨테이너에 4개의 코어를 할당하고
노드 1개당 1개의 컨테이너가 뜨도록 하면 더 빨라질 것이다.

레플리카스를 2로 낮추고 위와같이 리소스를 바꿔주었다.

노드 하나당 하나의 컨테이너가 할당되었다.

대략 평균 2초가 줄어든게 보인다.

리소스 사용량을 보니 ollama가 자체적으로 멀티프로세싱을 쓰는 것도 확인되었다.
최신 Llama3를 올려보자.

모든 CPU를 사용하고있다.
조크를 진지하게 진심으로 생성하고 있는지 phi 보다 오래걸린다.

평균 9초의 시간이 걸린다.
응답 속도는 이렇게 높일 수 있었지만
컨테이너 하나가 뜨는데 시간이 너무 오래 걸린다.
다음 글에서는 콜드스타트때에도 모델을 사용할 수 있도록 하는 방법을 연구해 봐야겠다.
'딥러닝 머신러닝 데이터 분석 > Langchain & LLM' 카테고리의 다른 글
| [LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 1 (2) | 2024.04.22 |
|---|---|
| [LangChain] 스스로 똑똑해지는 AgentRAG를 구현해 보자 (4) | 2024.04.14 |
| [LangChain] 프롬프트를 다듬어서 앱의 성능 높이기 (0) | 2024.04.06 |
| [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자 (1) | 2024.04.04 |
| [LangChain] 맛집 찾아주는 LLM을 만들어 보자. (1) | 2024.03.28 |




댓글