지면 상 또 작성 시간 상 이전 글들에서 작성한 부분은 과감하게 생략하고 넘어가도록 하겠다.
본 블로그의 아래 시리즈들을 참고하면 된다.
2020.12.03 - [Backend MLOps/개인 환경 구축 기록] - [ 자취방 워크스테이션 ] #1 첫걸음을 내딛어보자.
[ 자취방 워크스테이션 ] #1 첫걸음을 내딛어보자.
//1 나는 물리학과를 졸업했다. 원래 석사과정에 진학할 생각을 하고있었고 고체물리학이나 반도체쪽을 하지 않을까 생각중이었다. 그리고 딥러닝을 이용한 소리 해석으로 석사를 마쳐가는 중
davi06000.tistory.com
2023.08.27 - [Backend MLOps/On-premise setting] - [k8s] 라즈베리파이 클러스터링 -1
[k8s] 라즈베리파이 클러스터링 -1
라즈베리파이를 4대 사왔다. 연결해서 클러스터링을 연습 해보려고 한다. 필요한 준비물은 아래와 같다. 1. 라즈베리파이 2대 이상 2. microSD card 같은 수량 3. microSD card 리더기 4. hdmi to mini hdmi 케이
davi06000.tistory.com
2023.09.24 - [Backend MLOps/On-premise setting] - [k8s] Jetson Nano에 k3s 설치하고 워커노드로 구축하기
[k8s] Jetson Nano에 k3s 설치하고 워커노드로 구축하기
운이 좋게도 당근으로 젯슨 두대를 구했다. 젯슨의 기본적인 세팅은 간략하게 설명하고 넘어가겠다. 우선 젯슨은 ARM아키텍쳐기 때문에 역시 전용 OS를 사용하고 이 OS는 기본적으로 우분투 데스
davi06000.tistory.com
본격적으로 본문으로 들어가 보자.

엘레파츠에서 라즈베리파이5 2개, 액티브쿨러 2개, 아이씨뱅큐에서 5V5A C타입 전원 2개를 주문했다.
파이5부터는 발열이 심해서 액티브 쿨러는 어떤 형태로든지 필수라고 한다.
또 5V5A의 전원이 아직 우라나라에는 표준 규격이 아니라서 정품 충전기가 수입되지 않고 있고 구하기 어렵다고 한다.
아이씨뱅큐에서 파이5 전용 전원을 팔고 있으니 믿고 사보았다.

이전에 라즈베리파이 클러스터를 구성할때 사두었던 파이 전용 미니 랙이 있어서 거기에 조립해줬다.
기판의 규격이 동일해서 조립하는데 어려움은 없었다.
하지만 소소한 포트들의 위치들이 바뀌었으므로 구버전 포트 맞춤형 쉘들에는 안맞을 수 있다.

낭만합격이다.
이대로 전원, 스위치허브, 라우터 등을 연결해 주면 바로 사용이 가능하다.
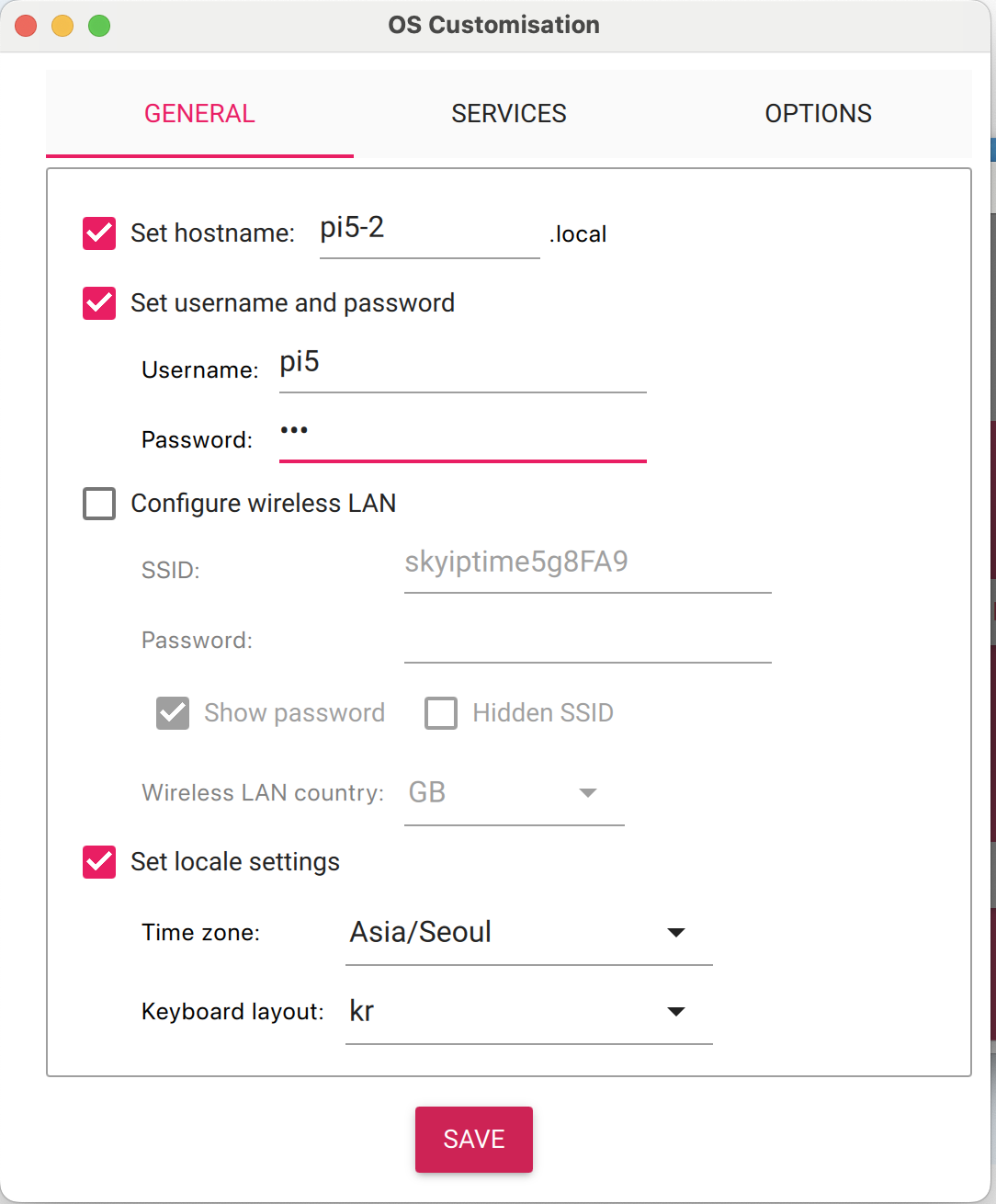
이렇게 호스트 네임과 유저네임을 잘 기억해 주고
서비스 탭에서 ssh를 활성화 해 주면 라즈비안라이트를 바로 사용할 수 있다.
DHCP를 통한 라우터 설정과 내부망에서의 노드간 접속에 관한 내용은 위의 본 블로그 글들을 참고해 주기 바란다.
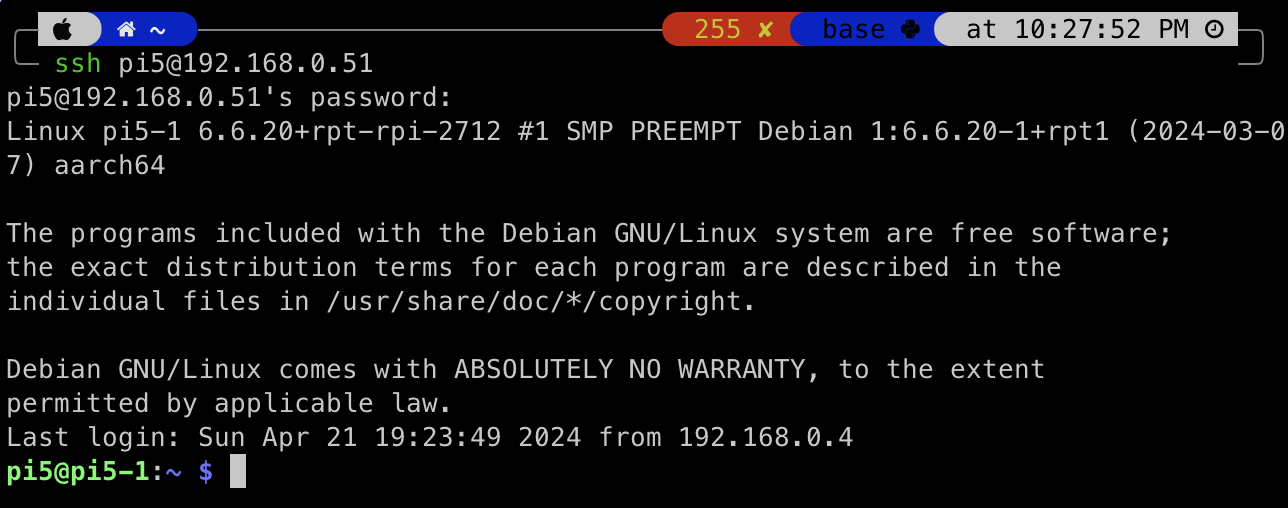
ssh를 통해서 각 노드들의 연결을 확인한다.
사진은 한장만 올렸지만 파이5 두대와 파이4 2G램 한대를 초기화하고 연결할 계획이라 모두 확인해 주었다.
우선은 클러스터를 구성해 보자.
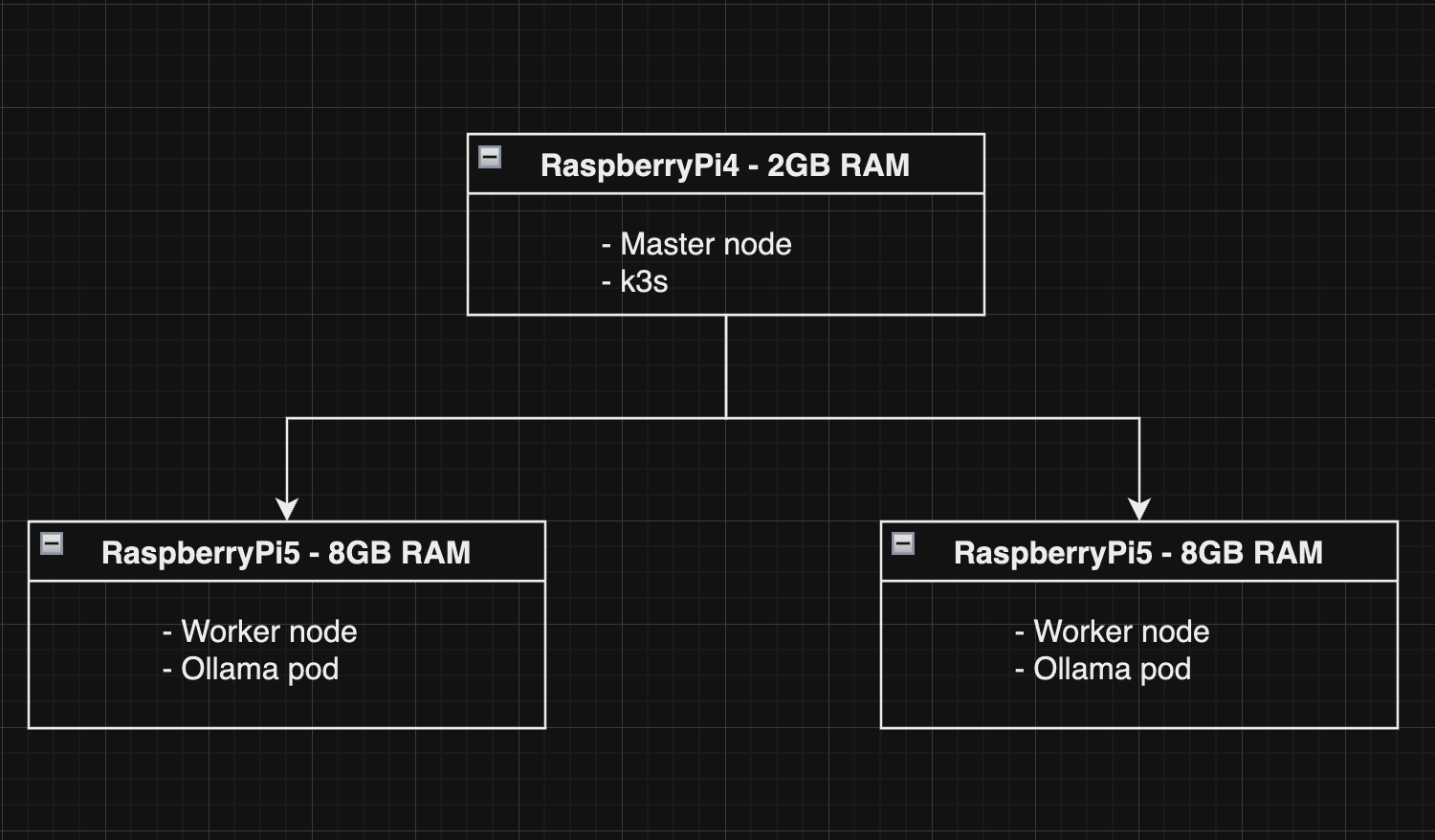
아주 무식하게 그린 모식도다.
마스터노드를 구성해 보자.
2GB램에서 정상적인 Kubeadm을 구동할 수 없으므로 K3s를 이용한 경량버전의 쿠버네티스를 깔아준다.
아래의 명령어들을 입력해서 vim을 깔고 부트컨피그 파일을 수정한다.
sudo vim /boot/firmware/cmdline.txt
# cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1
# 이 문구를 맨 앞에 추가
# 확인
cat /proc/cgroups | grep memory
# k3s install
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server" sh -
# 설치 확인
sudo k3s kubectl get nodes
# 토큰 확인
sudo cat /var/lib/rancher/k3s/server/node-token설치가 잘 안되면 리부트를 통해 모든 설정이 적용되도록 한다.
워커노드에는 굳이 k3s를 설치할 필요가 없으나
Ollama를 돌리기 위해서 다른 프로세스의 점유율을 최대한 낮추는게 좋겠다.
그러기 위해서 k3s를 이용해서 워커노드들도 구성해 준다.
sudo vim /boot/firmware/cmdline.txt
# cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1
# 이 문구를 맨 앞에 추가
# 확인
cat /proc/cgroups | grep memory
# agent install
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="agent" K3S_URL=https://<YOUR SERVER IP>:6443 K3S_TOKEN=<YOUR TOKEN> sh -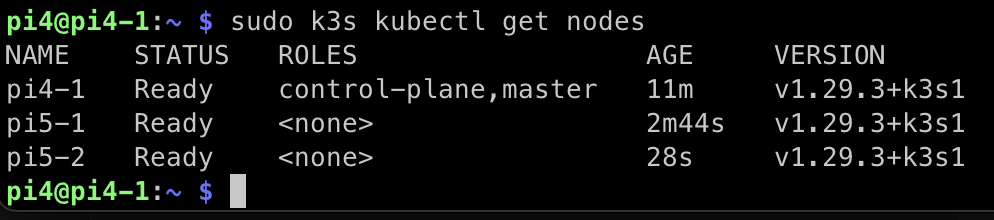
파이4-1 에 파이5-1, 5-2가 연결된 모습이다.
이제 클러스터가 준비되었으므로 파드를 생성하도록 하자.
파드를 생성하기 위해 Ollama의 사용법을 숙지하자.
설치를 마치고

아무 모델이 없으므로 최신 버전의 Llama3를 불러와보자.
킹론상 Llama2:13b 까지는 돌아갈 것이다.

정말 좋은 세상에 살고 있다

시간은 한참 걸리지만 문장이 생성되는 것을 볼 수 있다.
ollama의 공식이미지를 쓰면 뚝딱! 뭐가 될 줄 알았으나
인생이 늘 그렇듯 쉬운게 하나도 없다.
ollama 깡통 앱은 LLM이 하나도 없는 상태에서 서빙되는데
컨테이너 상에서 서빙이 시작된 다음부터는 다른 조작이 불가능해서 curl을 이용해서 LLM을 다운받는 api를 콜해야 한다.
내 지식이 아직 부족한 것인지 아무튼 지금 상황으로는
한 큐에 끝낼 수 있을 줄 알았는데 시리즈가 되어버렸다.
다음 글에서는 파드가 뜨는 동시에 LLM 모델까지 설치해서 이용에 지장이 없는 상태로 만들어 보자.
'딥러닝 머신러닝 데이터 분석 > Langchain & LLM' 카테고리의 다른 글
| [LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 2 (1) | 2024.04.28 |
|---|---|
| [LangChain] 스스로 똑똑해지는 AgentRAG를 구현해 보자 (4) | 2024.04.14 |
| [LangChain] 프롬프트를 다듬어서 앱의 성능 높이기 (0) | 2024.04.06 |
| [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자 (1) | 2024.04.04 |
| [LangChain] 맛집 찾아주는 LLM을 만들어 보자. (1) | 2024.03.28 |




댓글