2024.04.04 - [딥러닝 머신러닝 데이터 분석/Langchain & LLM] - [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자
[LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자
이전 글 참고 2024.03.28 - [딥러닝 머신러닝 데이터 분석/Langchain & LLM] - [LangChain] 맛집 찾아주는 LLM을 만들어 보자. [LangChain] 맛집 찾아주는 LLM을 만들어 보자. 아래의 글에 선행 내용이 있다. 2024.03.2
davi06000.tistory.com
이전글을 참고하길 바란다.
장소와 블로그를 검색할 수 있는 전문가 LLM을 붙여주고
그들끼리 서로 소통이 가능하게 한 다음
최종적으로 위치정보를 물어볼 수 있는 챗봇을 만들었다.
석촌 호수 에 커피마실만한 곳을 알려달라고 했다.

영어로 검색하고 알아보는 것을 알 수 있다.
영어로 프롬프트를 작성했기 때문이다.

역시 구글 플레이스 전문가LLM도 영어로 검색한다.
결과를 보면

나쁘지 않은 결과를 전해줬다.
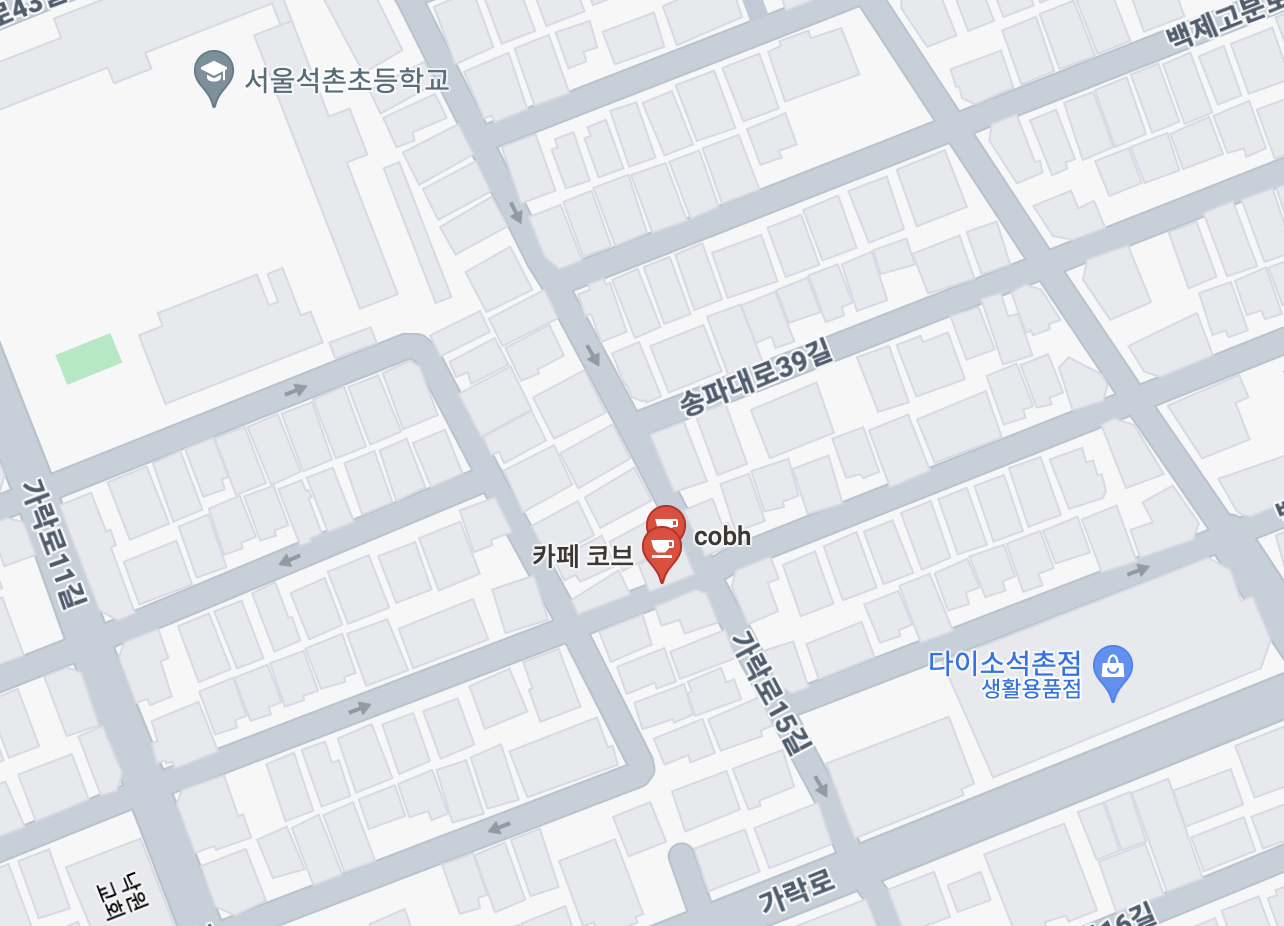
실재로 코브라는 까페도 있다.
그러면 다른 까페도 알고 싶다고 가정하고 알려달라고 해보자.

한국어로 질문을 이어 나갔을 때 메모리는 잘 동작하고
"한국어 질문에 대답"하는 테스크를 푸는 것에 집중하고 컨텍스트를 유지하지만
그 "한국어 질문"이 내포하고 있는 정보들을 이어나가는 컨텍스트는 유지하지 않는 것을 볼 수 있다.
이런식으로 CoT가 남기는 로그를 자세하게 보고 어떤 부분에서 어떤 착각을하는지 찾아낼 수 있어야한다.
메모리가 잘 동작하고 있는지 그렇지 않아서 에러가 났는지
혹은 LLM이 잘못 이해 할만한 프롬프트를 짰는지
그 외의 내용 접근에대한 장벽은 없는지
이런 것들을 판단할 수 있도록 최대한 많은 정보를 로그에 남기는 것이 좋다.
만약 이게 한국인들에게 서빙되는 앱이었다면 사용에 불편함을 유발할 것이 분명한 부분이다.
그렇다면 한국어로 모든 프롬프트를 고치면 어떨까?

이런식으로 영어였던 프롬프트를

이렇게 한국어로 번역했다.
플레이스 홀더를 유지하면서 내용은 그대로, 언어만 한국어로 바꾸었다.

Output Parser 를 커스터마이즈 하지 않았으므로 필요부분은 영어로 남겨둔다.
하지만 템플릿에서 관측 부분을 가로채서 우리가 결과를 넣어줘야 하므로

에이전트의 Stop word를 한국어로 추가해 주어야한다.
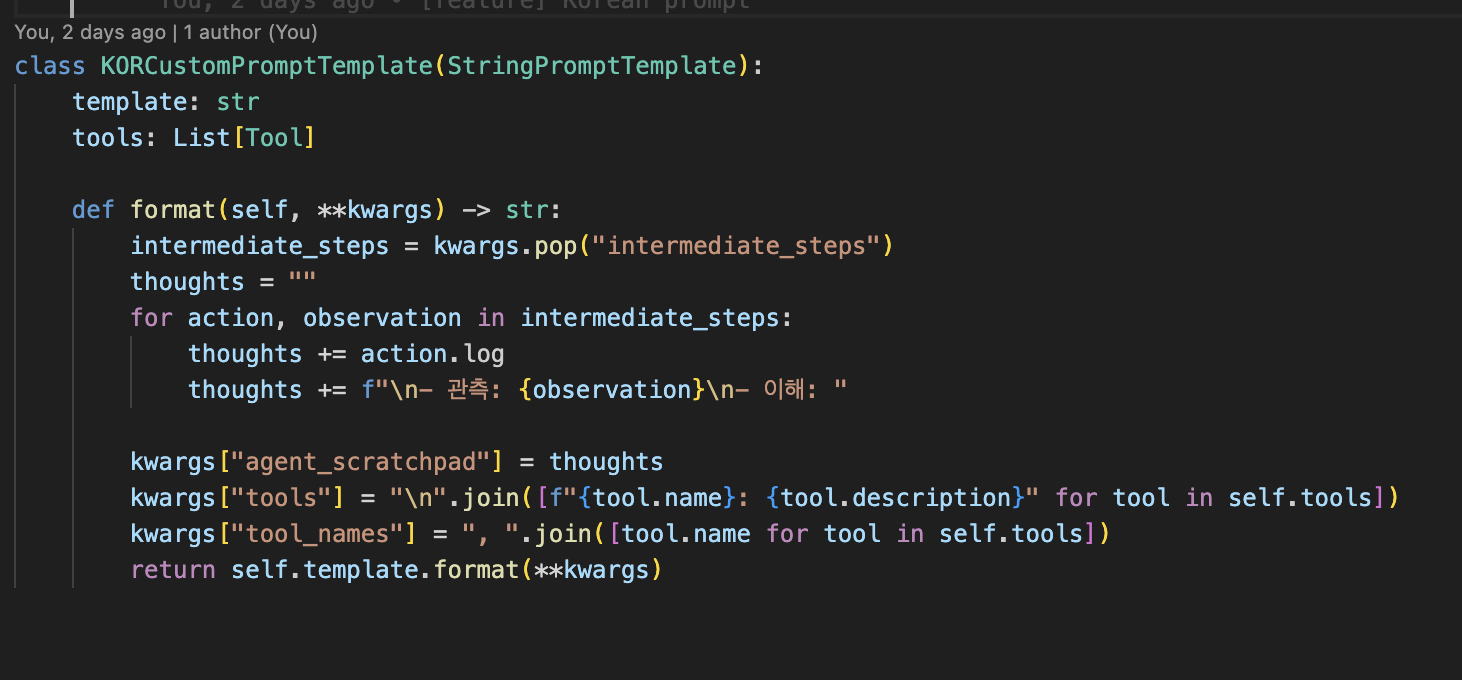
물론 아까 남겨두었던 플레이스홀더에 맞춰서 프롬프트 템플릿을 구성하고
CoT 핵심부분을 한국어에 맞게 맞춰준다.
이제 다시 돌려보자.

이번에는 한국어로 생각하고 한국어로 접근하고 있다.
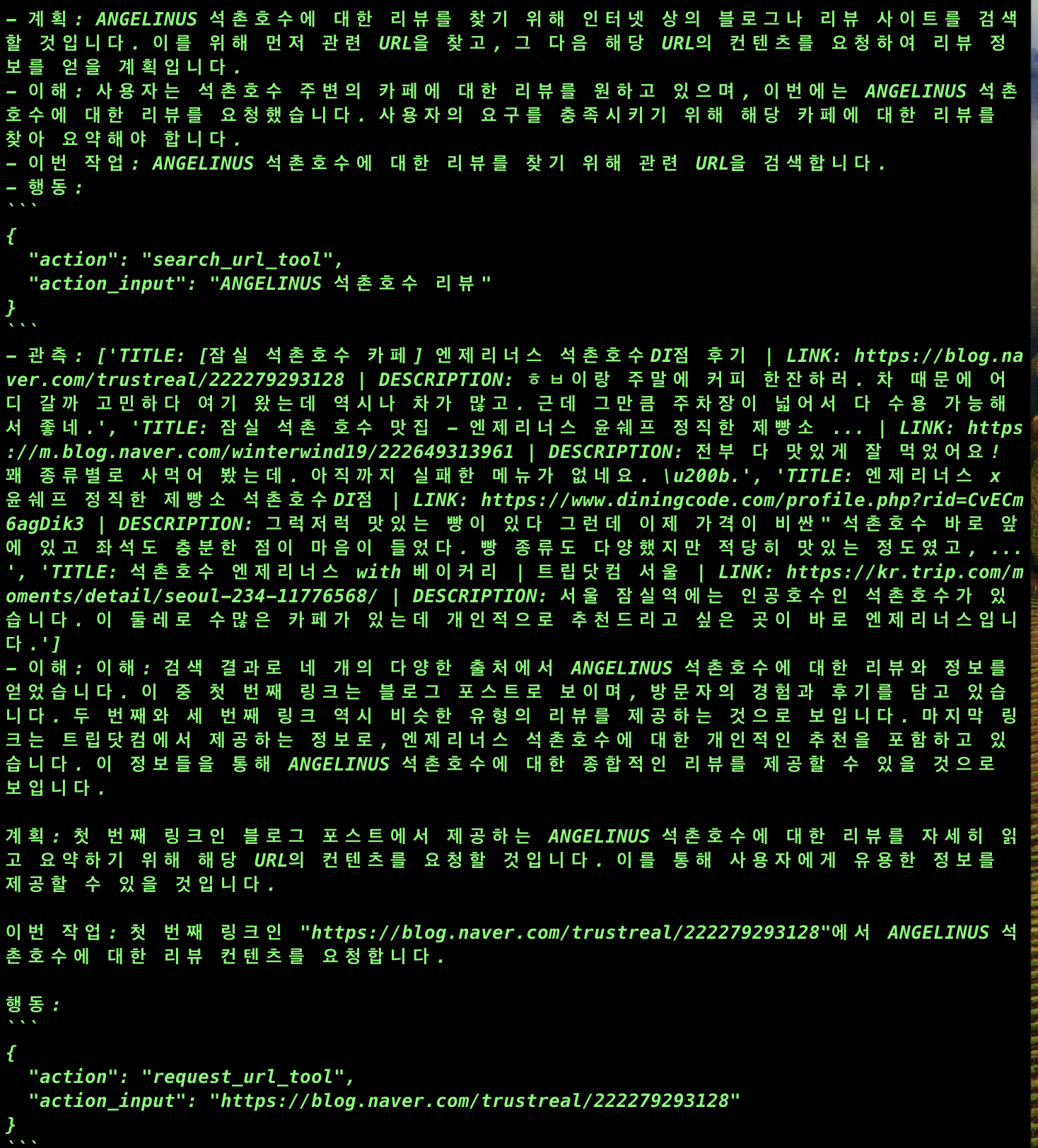
잘 수행하지 못하던 블로그 리뷰도 한국어로 검색한 결과를 한국어로 해석해서 접근하고 있다.

결과를 얻은 내용이다.

이 부분이 가장 큰 차이점인데
한국어로 계속해서 질문하고 이해하다보니 컨텍스트를 그대로 가지고 가는 것을 볼 수 있다.

전문가 LLM이 같은 내용을 전달했을때 정확한 정보를 얻지 못할 경우 스스로 판단하여 다른 분야의 전문가에게 문의하는 것도 볼 수 있다.

결과다.
결론적으로 LLM이 소통할 유저를 바르게 설정하는 것이 좋고
그 유저와 언어를 맞추는 것이 가장 좋다.
왜냐하면 "번역" 하는 작업 레이어가 추가될 경우
그것이 질의에 응답하는 것보다 더 우선순위를 가지는 작업으로 이해될 수 있기 때문이다.
그러한 우선순위를 판단하기 위해서는 CoT가 남기는 로그들을 잘 확인할 필요가 있다.
만약 검색엔진을 Naver로 바꾸거나 지역 특화적인 부분으로 바꾸면 성능은 더 올라갈 것임을 기대할 수 있다.
즉 LLM자체는 영어에 특화되어 학습된 모델이라 하더라도 도구가 다른 언어에 맞게 동작해야하면
그 언어로 프롬프팅을 할 수 있도록 유동적인 아키텍쳐 구성을 빌드하는 것이 좋겠다.
'딥러닝 머신러닝 데이터 분석 > Langchain & LLM' 카테고리의 다른 글
| [LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 1 (2) | 2024.04.22 |
|---|---|
| [LangChain] 스스로 똑똑해지는 AgentRAG를 구현해 보자 (4) | 2024.04.14 |
| [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자 (1) | 2024.04.04 |
| [LangChain] 맛집 찾아주는 LLM을 만들어 보자. (1) | 2024.03.28 |
| [LangChain Crawler] 랭체인과 LLM으로 크롤링을 해보자 (1) | 2024.03.26 |




댓글