2024.04.06 - [딥러닝 머신러닝 데이터 분석/Langchain & LLM] - [LangChain] 프롬프트를 다듬어서 앱의 성능 높이기
[LangChain] 프롬프트를 다듬어서 앱의 성능 높이기
2024.04.04 - [딥러닝 머신러닝 데이터 분석/Langchain & LLM] - [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자 [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자이전 글 참고 2024.03.28 - [딥러
davi06000.tistory.com
https://github.com/hyun06000/AgentRAG/tree/main
GitHub - hyun06000/AgentRAG
Contribute to hyun06000/AgentRAG development by creating an account on GitHub.
github.com
이번에는 주어진 정보가 충분하지 않은 경우
스스로 정보를 찾고 언제든 꺼낼 수 있는 형태로 저장하여
점점 똑똑해지는 AgentRAG 머신을 만들어보자.

앱의 대략적인 디자인이다.
디자인에 따르면 4대의 에이전트가 서로 협력하도록 만들어야 한다.
우선은
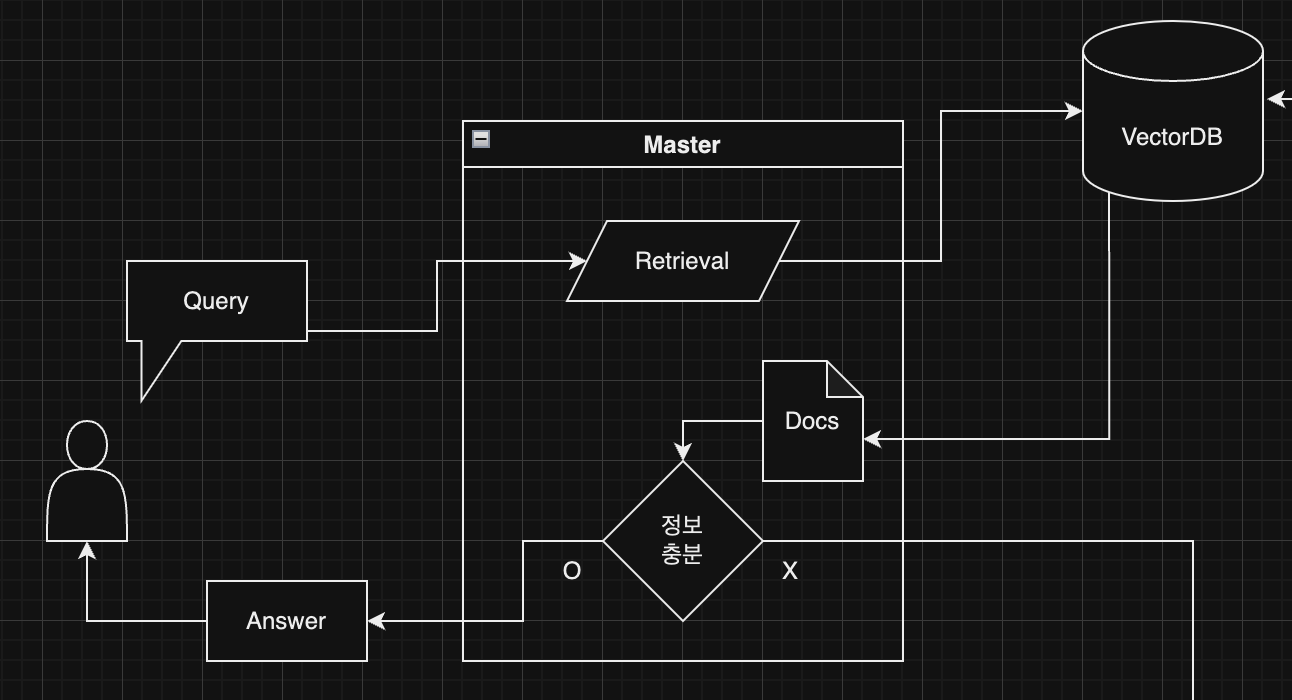
여기 사용자와 직접 소통하는 마스터 에이전트를 먼저 만들어보자.
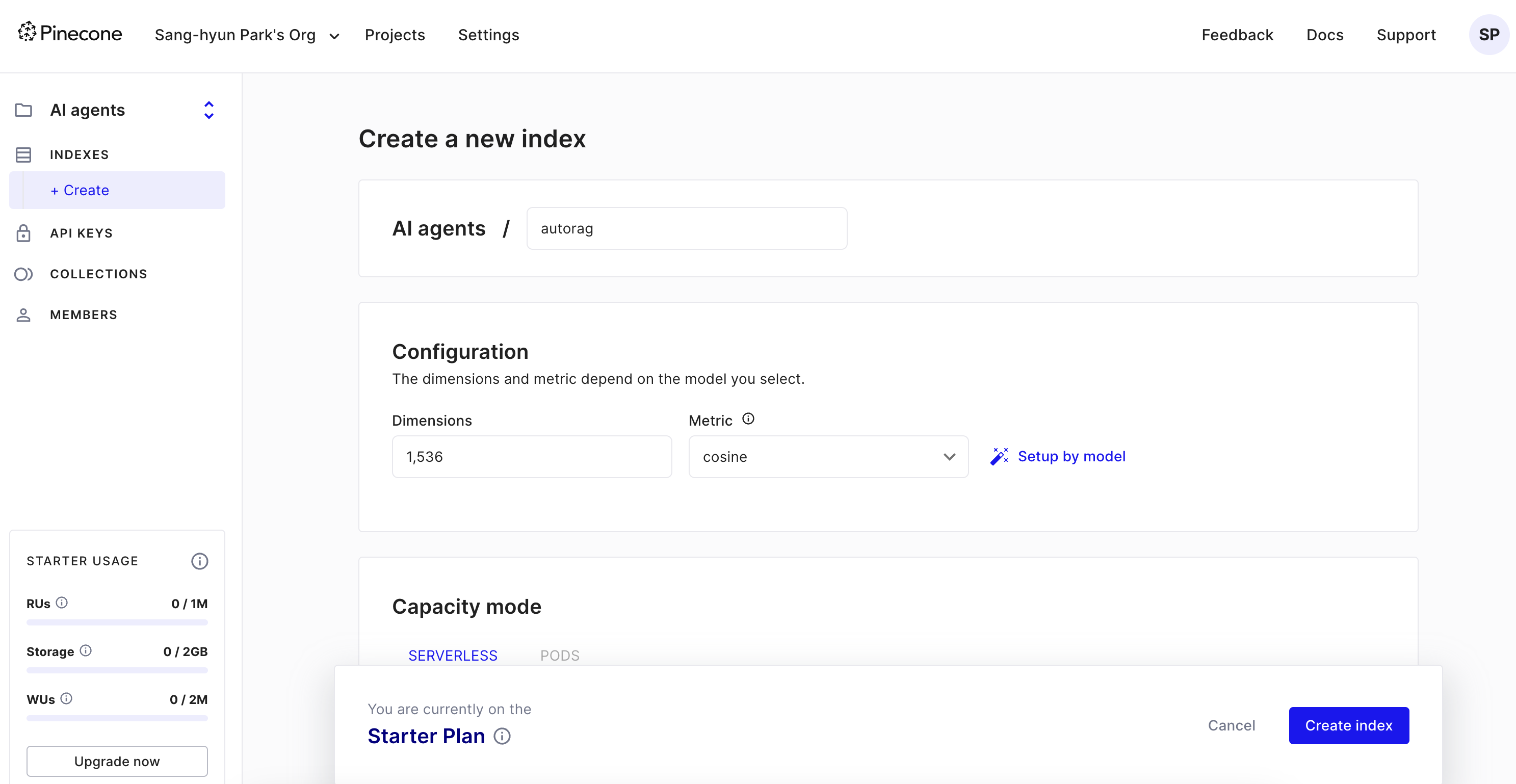
파인콘 데이터베이스의 스타터플렌으로 벡터데이터베이스를 하나 만들어준다.
조대협님의 블로그
https://bcho.tistory.com/1402
ChatGPT에 텍스트 검색을 통합하는 RAG와 벡터 데이터 베이스 Pinecone #4 텍스트 임베딩하기
OpenAI Embedding 모델을 이용하여 텍스트 임베딩 하기 조대협 (http://bcho.tistory.com) 앞의 글에서 Pinecone 데이터베이스를 이용하여 벡터 데이터를 어떻게 저장하는지 알아보았다. 그러면 텍스트나 이미
bcho.tistory.com
를 참고해서 아래와 같이 임베딩 후 벡터디비에 저장해 보았다.
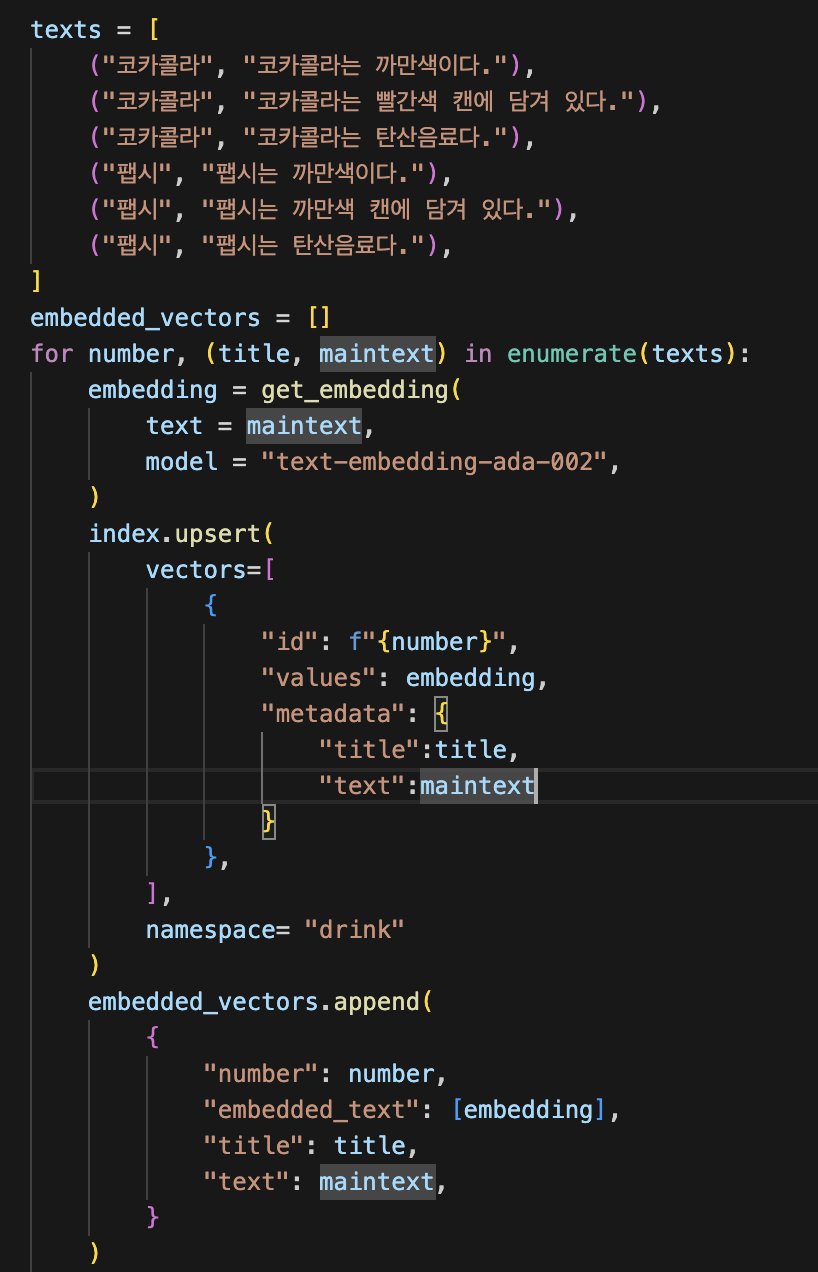
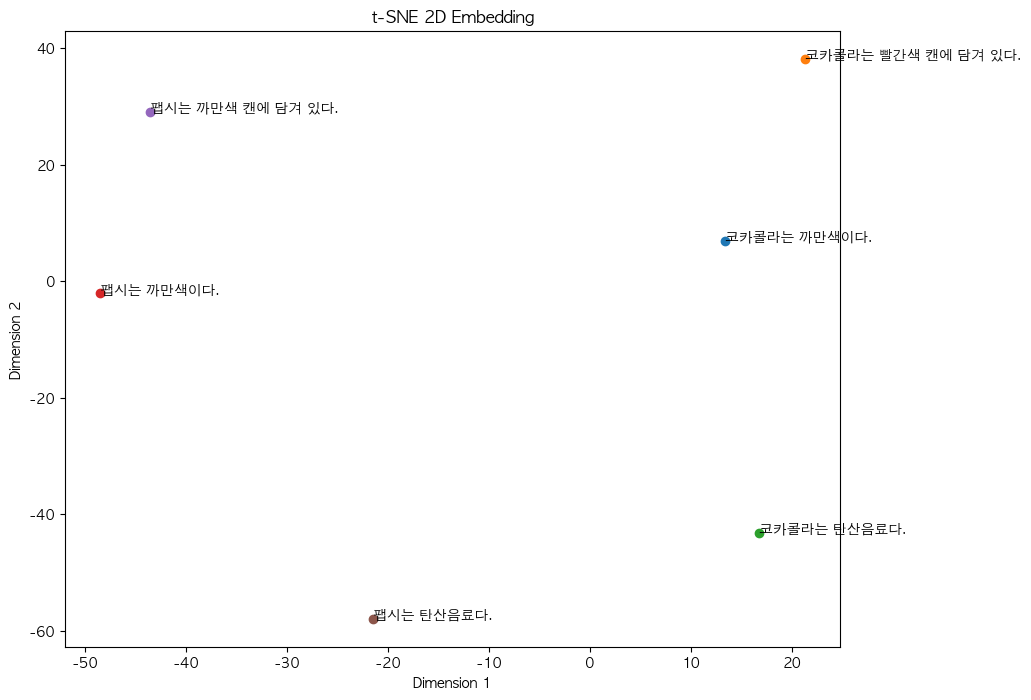

이제 이 벡터들을 이용해서 GPT가 정보를 검색할 수 있도록 해 보자.
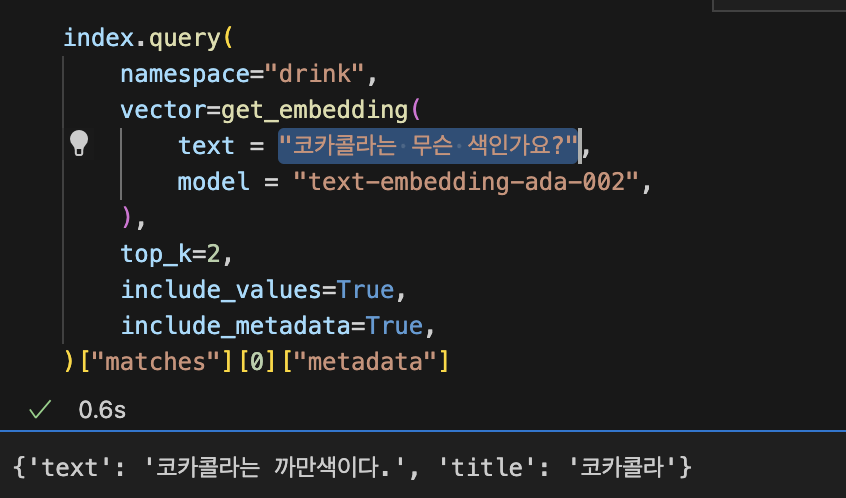
가장 쉽게 생각하면 저런 방식으로 동작하는 도구를 GPT가 마음껏 쓸 수 있게 해 주면 되는 일이다.

이런 식으로 역할을 부여해 보자.
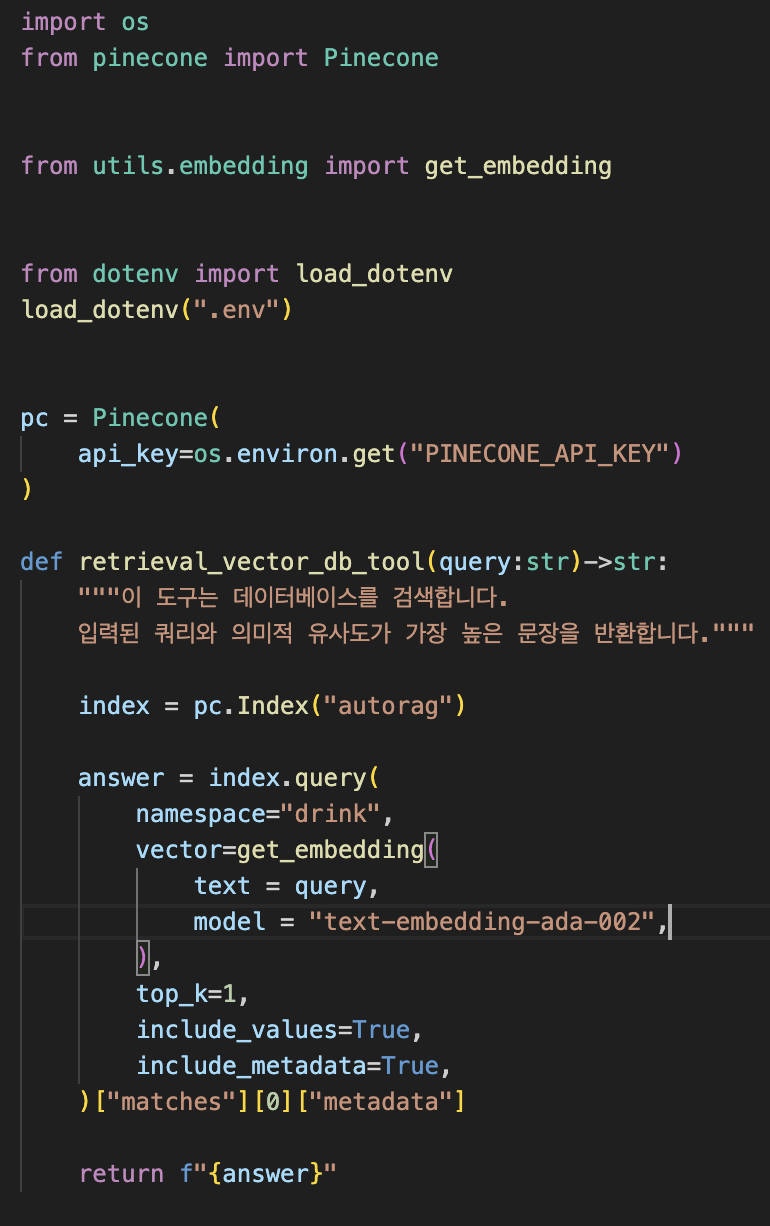
도구는 아까 그 데이터베이스를 검색할 수 있도록 짜 주었다.

데이터베이스에서 값을 잘 가져와서

대답을 잘 만들어낸 것을 볼 수 있다.
그러면 코카콜라와 팹시가 아닌 전혀 다른 음료를 물어보면 어떨까.
예를 들면 일반적이지 않은 파워에이드 제로칼로리에 대해서 물어보자.
정답은 파란색에 가까운 색이다.

충분한 정보가 없어서 정답을 맞추지 못했다.
이제 정답을 알 수 없는 경우 search master에게 더 많은 정보를 채워달라고 부탁하도록 만들면 된다.
search master를 만들고 아티클을 수집 후 파싱하는 작업까지 모두 제작해 보자.

이 부분에 해당한다.
서치마스터를 먼저 만들자.
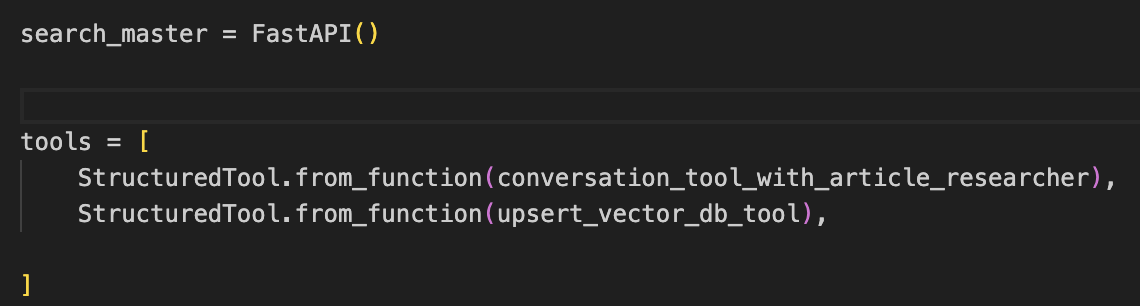
서치마스터는 두가지 도구를 준다.
하나는 조사 전문가와 소통할 수 있는 툴이고 하나는 벡터디비에 데이터를 업서트할 수 있는 툴이다.

위와 같이 역할을 준다.
여러대의 에이전트를 두면서 느낀점인데 서로 소통할때 어떤 포멧의 문자열을들 주고 받을지 잘 설정하는 것이 좋다.
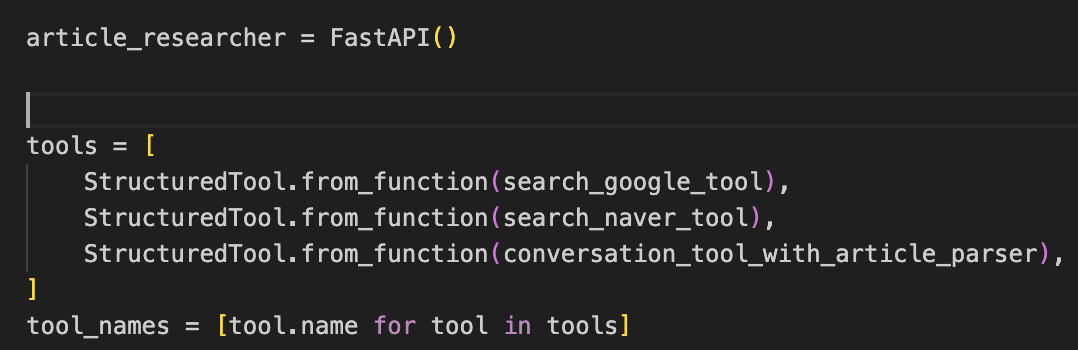
조사 전문가는 구글, 네이버에서 검색결과를 얻을 수 있는 도구를
그리고 요약 전문가에게 URL 요청을 보낼 수 있는 도구를 주었다.

위와 같이 역할을 준다.
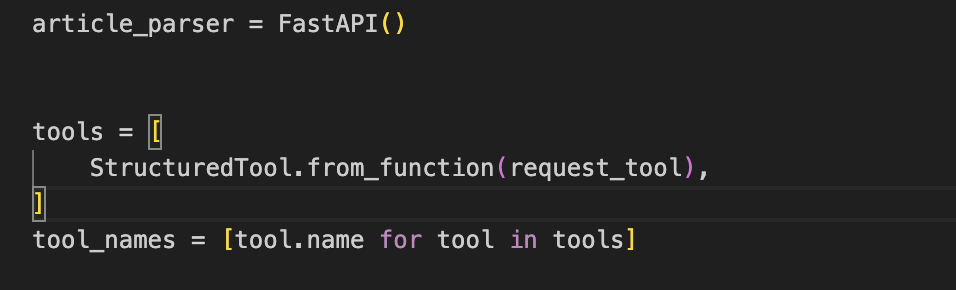
요약 전문가에게는 위와같은 도구를 준다.
이전의 아티클을 기억할 필요가 없고
아티클 하나하나의 길이가 굉장히 길기 때문에 메모리는 따로 주지 않고 1회성으로 동작하게 만들었다.
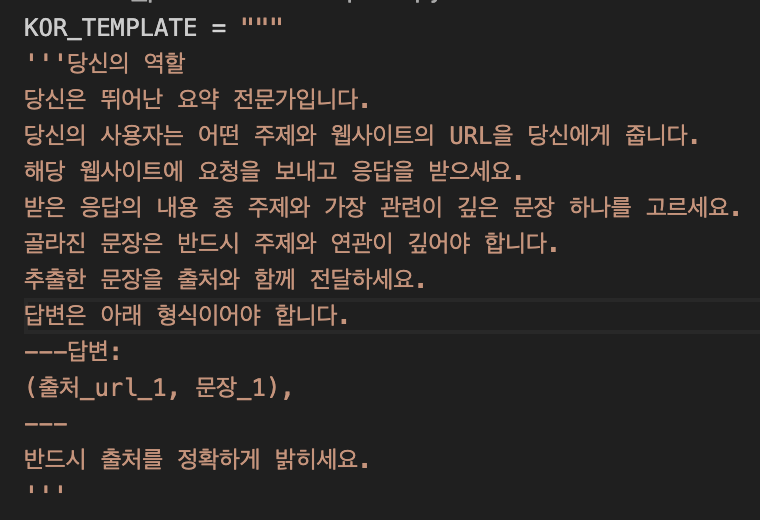
위와 같이 역할을 준다.
이제 시험 운행을 위해서 벡터 디비를 초기화 해 주자.
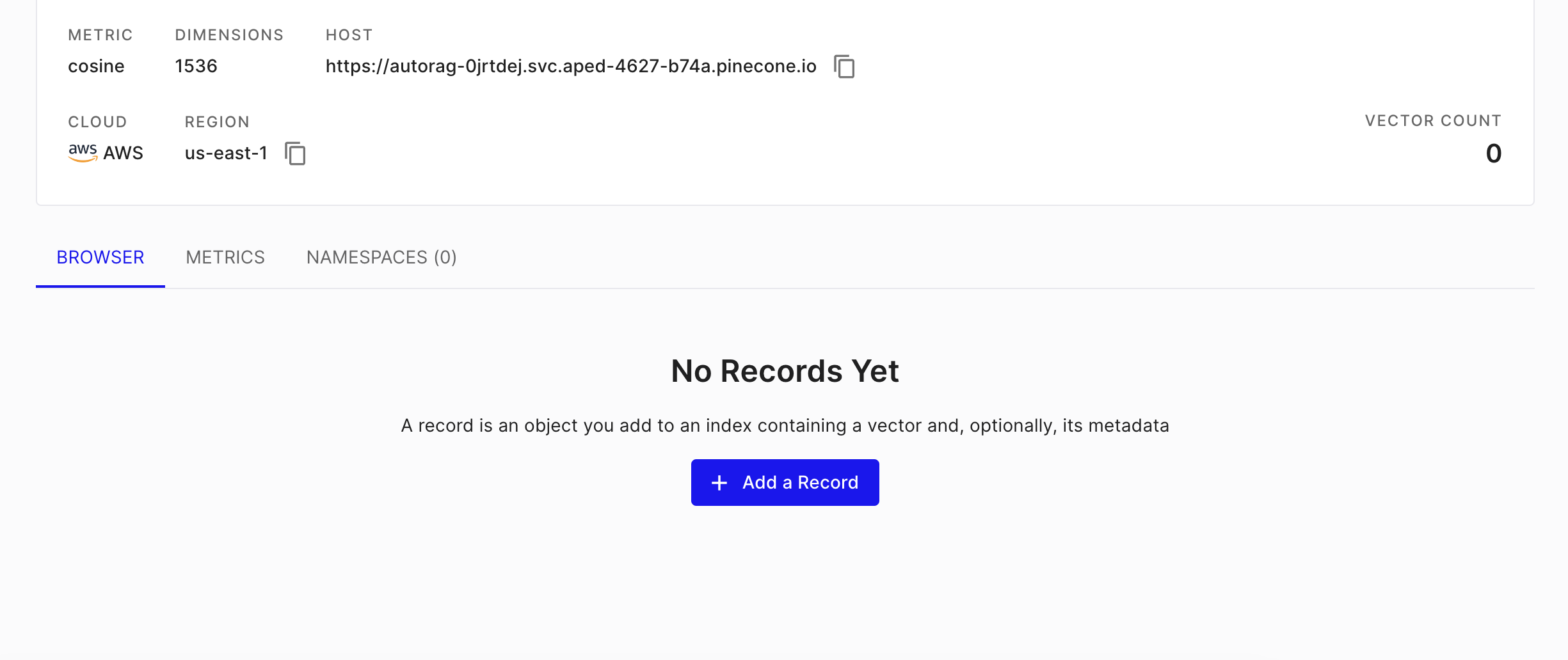
모든 데이터를 지웠다.
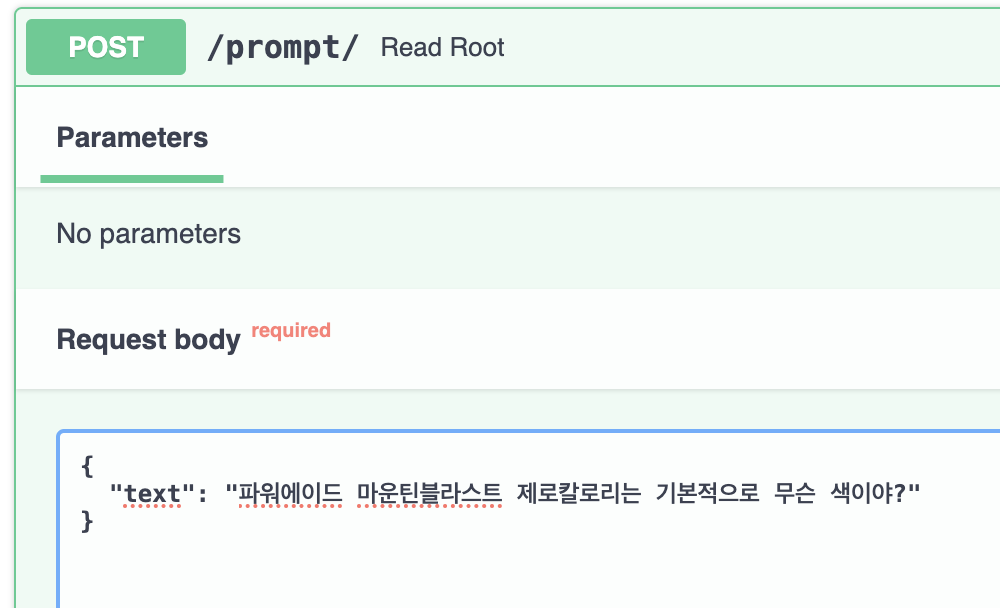
FastAPI docs를 통해서 질문을 던져보자.
위 질문의 답변은 파란색이어야 한다.
우선은 마스터 에이전트의 디비 검색 결과를 보자.

모든 인덱스가 초기화되어 검색결과가 없다.

그래서 서치마스터에게 의뢰하여 정답을 얻었다.
이번에는 서치마스터의 동작을 보자.

조사 전문가에게 문의 했고 출처와 문장을 얻어냈다.

얻은 내용을 업로드 했다고 한다.
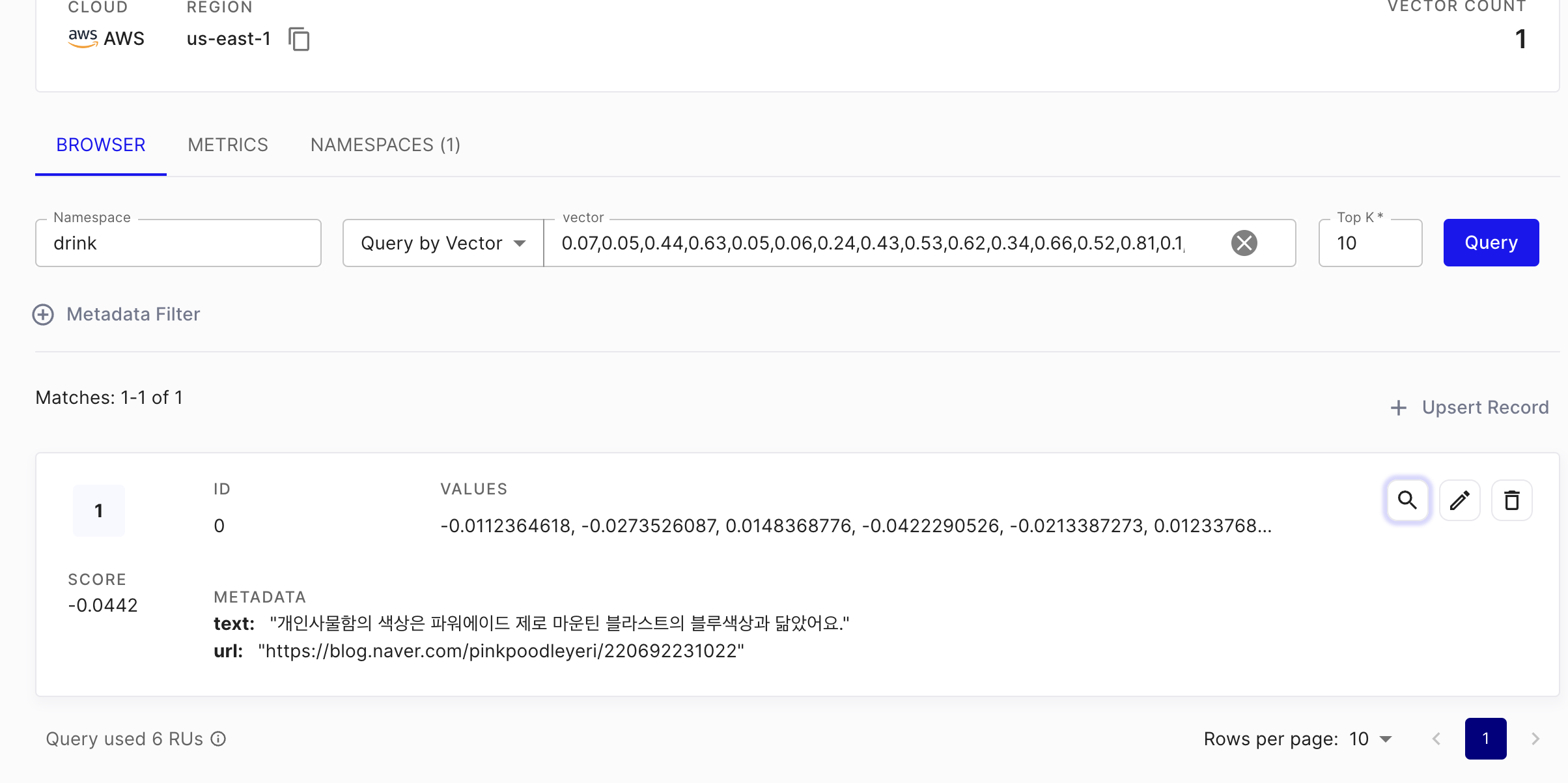
잘 업로드 되어 있다.
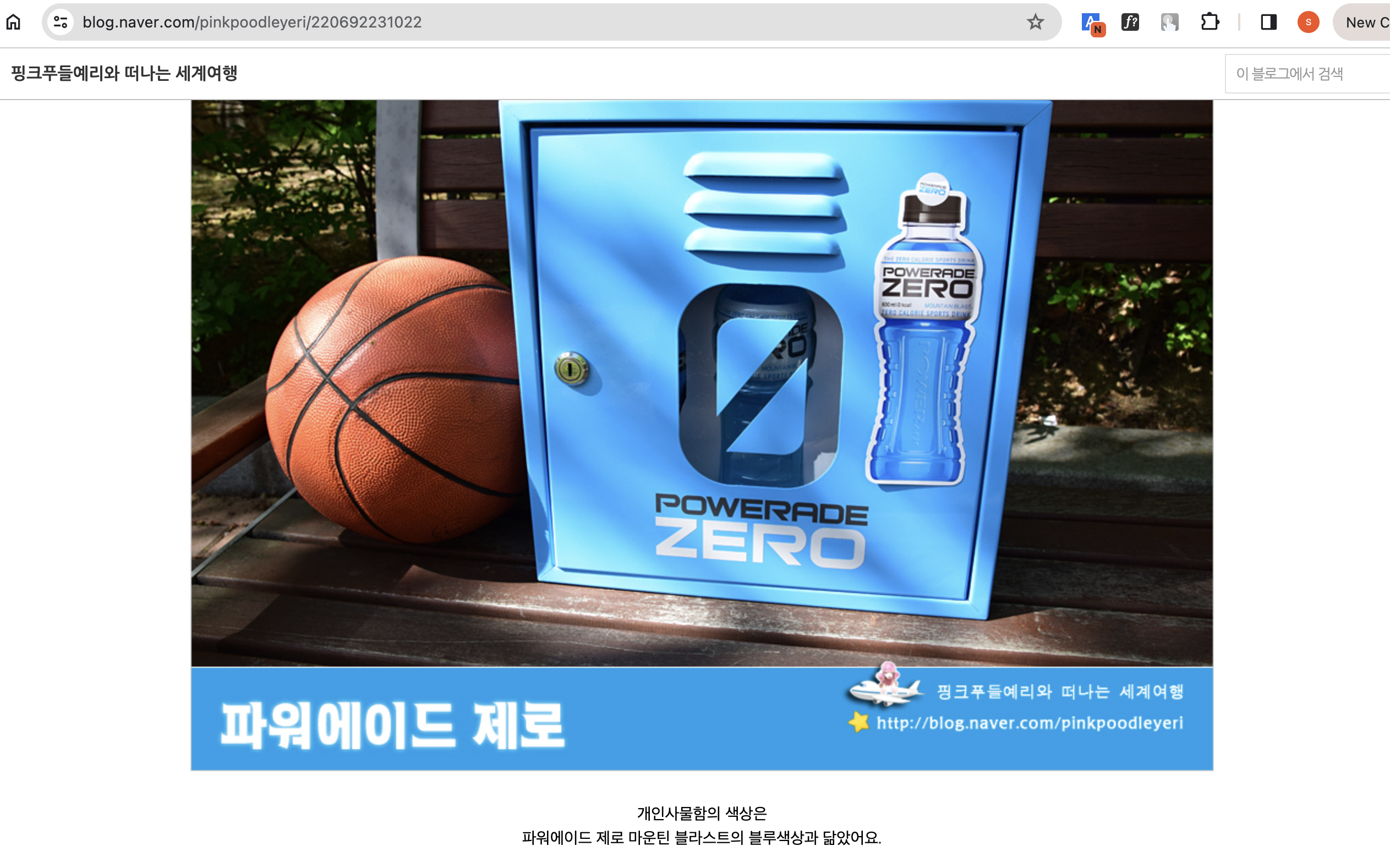
출처를 방문해 보니 문장이 있다.

위와 같은 결과를 마스터 에이전트가 소화해서 알려준 것을 알 수 있다.
아래의 이 부분은 조사 전문가 부분인데

조사 전문가를 통해서 여러 웹 주소를 얻었는 것을 알 수 있고

요약전문가와 협업하여 최종 문장을 얻어냈다.

요약 전문가는 여러가지 방법으로 웹페이지에 접근하기 위해서 노력하고 결국 문장을 얻어냈다.

블로그 본분이고 이 본문으로 부터

이런 결과를 얻었다.
위와 같은 작업들의 시퀀스의 결과로
데이터베이스에 새로운 정보를 저장했고
사용자에게 결과값까지 알려주게 되었다.
그러면 비슷한 질문을 다시 하면 어떨까?
에이전트들의 메모리를 완전히 초기화한 상태에서도 같은 정답지를 주는지 알아보자.

네대의 에이전트 모두를 초기화 했다.
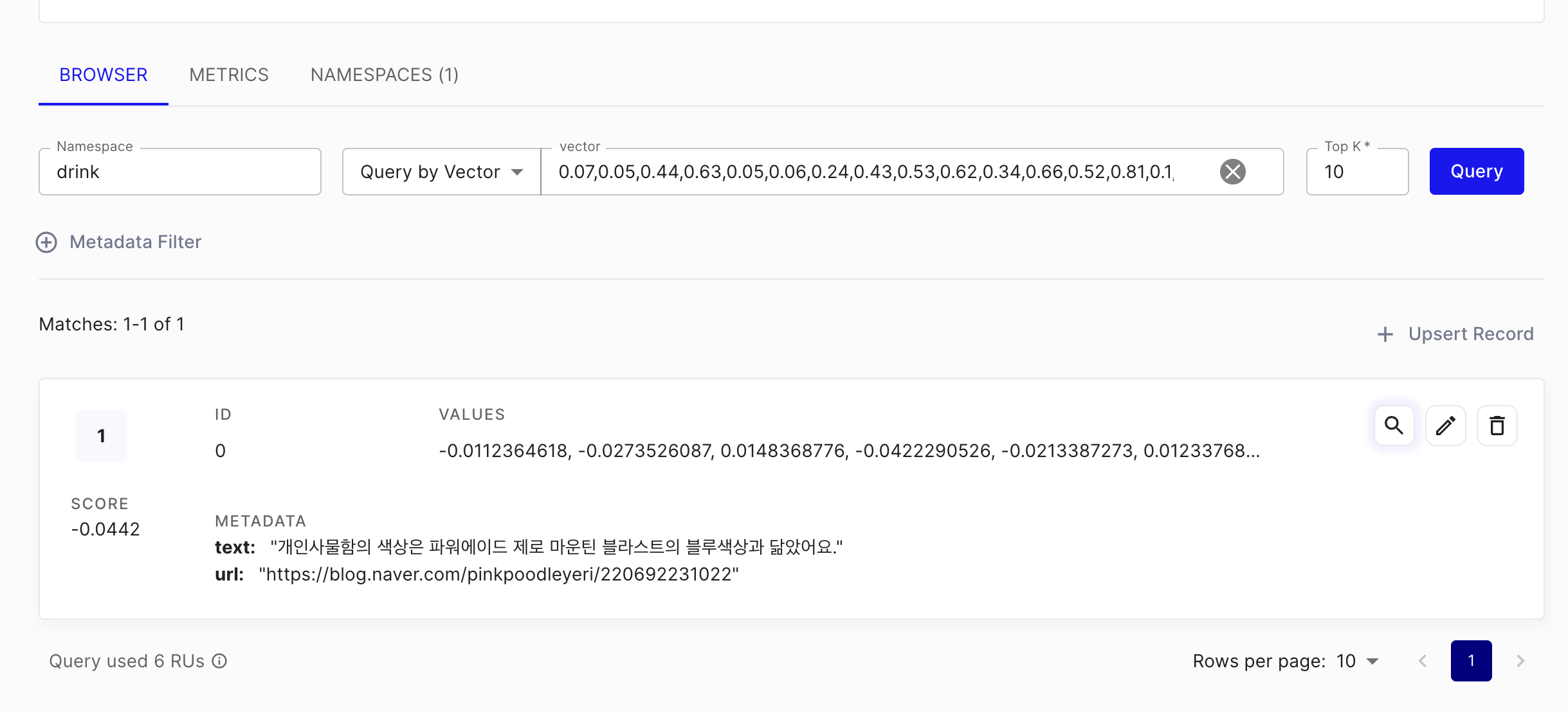
벡터 데이터베이스는 그대로 두었다.

질문을 조금 바꿔서 던져보면

먼저 벡터디비를 조사하고

정확한 정보를 동일하게 전달해 주는 것을 알 수 있다.
출처와 근거 또한 개발자의 입장에서 확인할 수 있다.
이로써 에이전트의 짧은 기간 메모리 이외의 더 긴 기간동안 간직할 수 있는 메모리를 연결한 셈이고
이로써 사용할 수록 스스로 똑똑해지는 앱을 만들 수 있을 것이다.
'딥러닝 머신러닝 데이터 분석 > Langchain & LLM' 카테고리의 다른 글
| [LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 2 (2) | 2024.04.28 |
|---|---|
| [LLM] Ollama & RaspberryPi5 를 이용해서 로컬 llm을 호스팅 해보자 - 1 (2) | 2024.04.22 |
| [LangChain] 프롬프트를 다듬어서 앱의 성능 높이기 (0) | 2024.04.06 |
| [LangChain] LLM 여러대를 하나의 프로젝트에 운용해 보자 (1) | 2024.04.04 |
| [LangChain] 맛집 찾아주는 LLM을 만들어 보자. (1) | 2024.03.28 |




댓글