1) 강의 복습 내용
CNN은 더 이상 배울게 없다고 생각했는데 그게 아니었다.
역시 고수들의 통찰은 언제나 뭔가가 있다.
흔하게 찾을 수 없었던 부분들을 정리해서 남겨보겠다.
한줄로 요약하면 parameter의 수가 적어질 수록 모델의 성능이 좋다.
Convolution layer 의 도입으로 신경망의 크기가 얼마나 줄어들었는지
말로만 말하면 잘 느낌이 안온다.
숫자로 봐도 '음 많이 줄었군' 정도의 느낌이지 크게 와 닿지 않는다.
컴퓨터 비전의 혁신을 가져온 CNN 인 만큼 눈으로 보면 딱 알 수 있다.
1993년도에 찍었다는 이 영상을 볼 때 마다 기가 딱 막힌다.
가끔 인공지능을 하는 사람들을 만나면
어떠한 신비주의에 매료되어서 수학적인 근간이나 고전적인 모델들에 대한 존중이 없는 경우가 종종 있다.
그런 사람들은 딥러닝이 블랙박스라고 주장하지만
그럼에도 많은 수학적인 기반들과 머신러닝의 깊은 역사들이 여전히 딥러닝을 튼튼하게 지지하고 있다.
나는 연구를 할때 "파라미터의 수를 줄이는 모델 구조가 좋은 모델이다" 라고 외우듯이 알고있었다.
그 이유는 computing 파워가 한정적이므로 작은 모델은 자원에대해서 자유롭게 되기 때문에
무거운 모델보다 가벼운 모델이 무조건 좋은 모델이라고 생각했었다.
지금 생각하면 그건 너무 단편적인 생각이었다.
그러면서도 그때,
한편 CNN이 MLP 보다 좋은 성능을 발휘하는 이유는 무엇인가에 대한 나름의 고찰은 또 하고 있었다.
많은 자료를 접하고 내린 몽롱한 결론은
MLP는 data point 전체에 서로 독립적인 가중치를 곱하므로
데이터 공간 전체에서 특징이 밀집된 영역에 대한 강한 학습이 일어나고
상대적으로 특징이 sparse한 영역의 학습이 어려워지지만
CNN의 경우 어떤 하나의 datum에서도 굉장히 국소적인 영역의 특징을 추출하므로
filter의 입장에서는 비교적 균일한 feature map을 학습하게 된다.
라는 아주 지금 읽고 말하기에도 어려운 추상적인 내용이었는데
지금은 그냥 한마디로 'parameter sharing 때문이다.' 라고 말한다.
그 이유는 아래와 같은데
1. 어떤 parameter가 광범위하게 공유 가능하다면 그것은 이미 generalization되어있다는 뜻과 일맥 상통이다.
2. 그러므로 더 넓게 공유 가능한 parameter를 찾아내는 학습 방법은 더 general한 모델을 찾을 수 있는 방법이다.
3. 그러므로 CNN이 MLP보다 성능이 더 좋다.
라고 깔끔하게 정리가 된다.
이게 내가 이번 강의에서 들은 CNN의 정수다.
(그리고 이 내용은 RNN까지도 이어진다.)

모델의 파라미터는 줄어들고 성능은 향상되는 것을
단지 computational cost 관점에서만 접근했던 내 머리가 박살이 나버렸다.
어떨땐 아주 짧은 시가 장황한 글보다 더 많은 의미를 담고 있을 때가 있다.
모델의 파라미터가 줄어들 수록 성능은 더 좋아진다.
그런데 이게 "그럼 그냥 파라미터를 줄여버리면 되지 왜 안줄임" 이라는 말이 아니고
당연히 더 작아도 되는 수학적인 이유가 있을 때 비로소 '더 작은 모델'을 만들 수 있다.
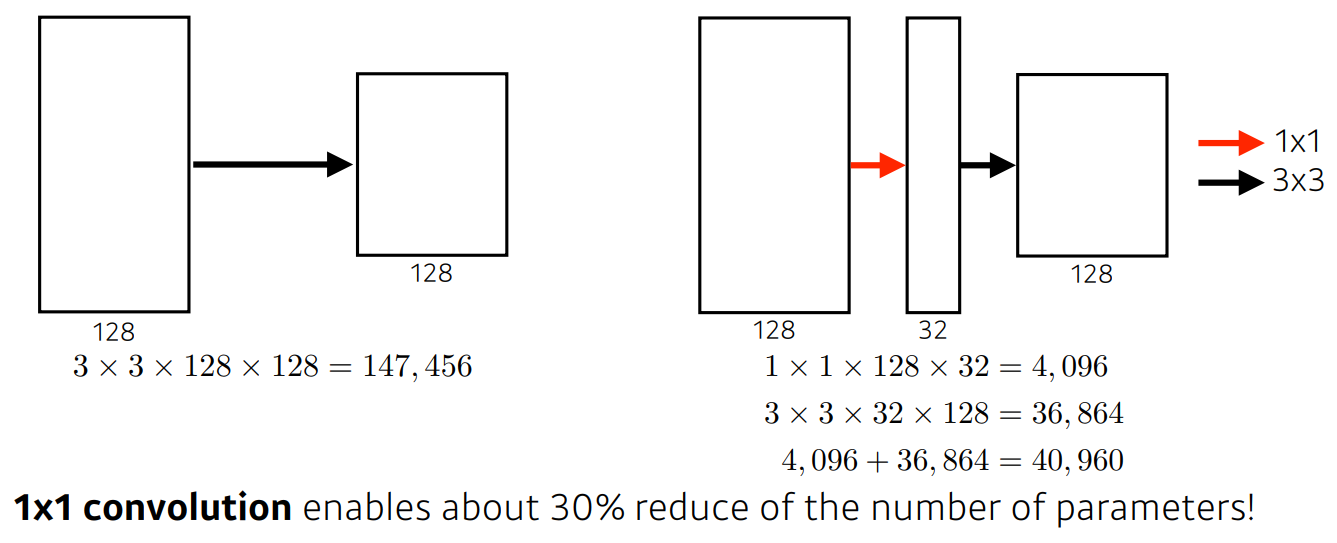
이런 point-wise-convolution을 쓰는 구조 예를 들면 MobileNet 같은 경우는
단지 1x1 필터층을 사용했다는 이유로 굉장히 파라미터가 줄어드는 것을 볼 수 있는데
이것은 합성함수의 개념에서 parameter가 곱해지는 경우의 수를 보면
결국 3x3의 필터가 1x1필터의 결과 9개를 연산하므로
채널방향으로 더 다양한 모수를 추정하는 복잡도 높은 합성함수가 만들어지는 것이다.
즉 왼쪽의 3x3 conv 연산의 필터가 원래 데이터를 국소적으로 보는 receptive field와
오른쪽 3x3 conv 연산의 필터가 보는 receptive field가 같지만
point-wise-conv 의 필터가 공유되고 있으니 왼쪽 연산이 더 일반화된 필터연산이라는 이야기다.
그 외에도 다양한 이미지 분류 모델을 소개해 주셨고
객체인식모델까지 소개해 주셔서 정말 풍성한 강의였다.
2) 과제 수행 과정 / 결과물 정리
기본적인 모델설계에 대한 pytorch 강의와 실습과제가 있었다.
3) 피어세션 정리
머신러닝에서 확률이 뭘까를 이번 기회에 팀원들에게 설명하기 위해서 깔끔하게 정리할 수 있었다.
확률이 어려운 이유는 정확한 명제를 수립하지 못하기 때문인데
확률을 표현하는 기호들이 모두 추상적인 편이기 때문이다.
특히 확률은 그 이름답게 한 6~70% 정도 알고 있을 수도 있고 아닐 수도 있으면
안다고 생각하기 때문에 공부를 하면 할 수록 3~40%의 오차가 매 단원 누적되게 된다.
이번 피어세션에서 나누었던 이야기는 나중에 잘 정리해서 블로그에 올려야겠다.
4) 학습 회고
이고잉의 git 강의를 라이브 직강으로 들었다.
이하 자세한 설명은 생략한다...
'딥러닝 머신러닝 데이터 분석 > BoostCampAITech' 카테고리의 다른 글
| [ BoostCamp ] Day-12 학습로그( Generative model ) (0) | 2021.08.18 |
|---|---|
| [ BoostCamp ] Day-11 학습로그(RNN) (0) | 2021.08.15 |
| [ Boost Camp ] Day-9 학습로그 (0) | 2021.08.10 |
| [ Boost Camp ] Day-8 학습로그 (0) | 2021.08.10 |
| [ Boost Camp ] BPTT를 이해해 보자 (4) | 2021.08.09 |




댓글