본 문서는 강의의 내용을 토대로 다른 자료들을 공부하고 취합하여 재 해석한 내용으로 강의 내용과 많이 다를 수 있음.
이하 모든 출처가 생략된 자료는 모두 Boost Camp AI Tech의 자료에서 발췌한 것임을 밝힘.
// 모수(parameter)
딥러닝을 포함한 머신러닝이 빅데이터를 요구하는 이유는 "통계적 추론"에 근거하기 때문이다.
따라서 딥러닝을 바르게 이해하고 정확한 직관을 가지기 위해서는
통계적 추론이 어떤 방식의 접근인지 이해할 필요가 있다.
통계적 추론에는 크게 두가지 방법론이 있다.
한가지는 모수적 방법론이고 다른 하나는 비모수적 방법론이다.
모수는 어머니가 되는 수라는 의미로 분포를 결정하는 매개변수들을 의미한다.
예를 들어서 어떤 분포를 모아서 히스토그램을 그리면 반드시 정규분포를 따른다는 사실을 알고 있다 가정하면
정규분포는 평균이 어디인지, 또 분산이 얼마나 크게 벌어져있는지만 알면
데이터를 충분히 많이 모으지 않아도 그 분포를 정확하게 그릴 수 있다.
그리고 그 분포를 통해서 아직 관측하지 못한 데이터의 값도 추정할 수 있다.
이때 분포를 결정하는 '평균'과 '분산'을 정규분포의 모수, 혹은 매개변수(parameter)라고 한다.
만약 소량의 데이터만을 모아서 이런 '모수'를 추정할 수 있고
그 모수를 통해서 분포를 추정할 수 있으면 우리는 이것을 '모수적 방법론'이라고 한다.
이때 모수를 추정할 수있는 데이터를 모으는 실험을 선행하여 추정하므로
선험적 확률로 부터 모수를 추정한다고 할 수 있다.
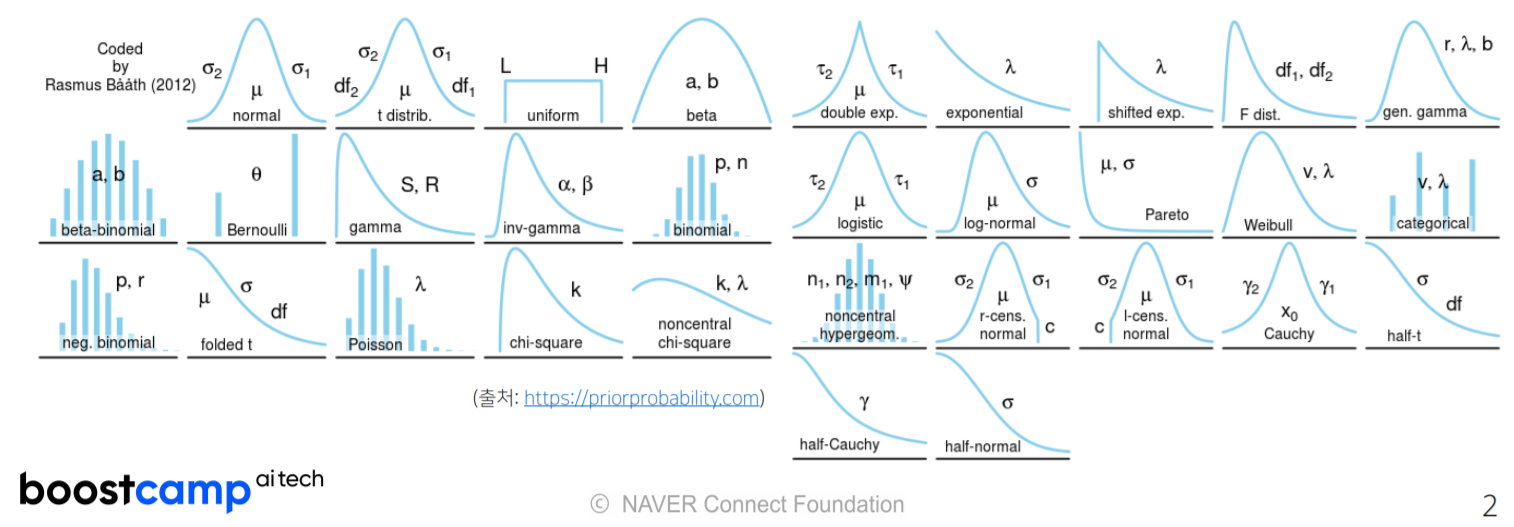
하지만, 일반적으로 실재 데이터는 분명 어떤 분포를 따르지만 그 분포는 간단한 식으로 표현되지 않는다.
따라서 우리는 추정해야하는 모수가 너무 많거나 혹은 각각의 데이터마다 모수가 달라지는 경우
관측한 데이터 세트로 부터 정확한 모수를 추정할 수 없으므로 '비모수적 방법론'을 통해 분포를 추정한다.
비모수적 방법론에서는 모수를 정확하게 추정하지 못한다고 가정할 뿐
데이터가 따르는 어떤 분포가 반드시 존재하고 그 분포의 모수 또한 존재한다고 본다는 점에서
모수적 방법론과 공통점을 가진다.
그렇다면 비모수적 방법론은 어떻게 성공적인 모델을 추정할 수 있을까.
이때 사용하는 방법이 바로 목적함수를 설정하여서 추정의 위험도를 측정한 뒤
이 위험도가 최소화되는 방향으로 모델의 파라미터를 조정해가는 '학습'이다.
학습을 통해서 일정 수치 이하의 위험도를 가지는 모델을 우리는
근사적으로 추론된 분포를 따른다고 생각하게 된다.
기계학습에서도 핵심적인 부분은 바로 이 근사적 추론으로 얻어진 분포이며 특히
데이터 x 가 주어지면 그때 라벨 y가 관측될 확률 분포를 얻는 과정으로 학습을 이해해야한다.
// 모수 추정
비모수 추정은 우리가 얼추 알고 있는 머신러닝 방법들이 방법들이 금방 떠오른다.
하지만 모수추정은 생각보다 오히려 금방 떠올리기가 쉽지 않다.
여러가지 이미 잘 알려진 분포들이 존재하므로 데이터를 모아 히스토그램을 그려보면
어떤 분포를 따르는 데이터인지 대략적으로 감을 잡을 수 있다.
강의에서 임성빈 교수님은 이 부분을 언급하면서 히스토그램을 기계적으로 분석하는 것이
그렇게 좋지 못한 방법이라고 이야기하셨다.
데이터를 분석하는 분석가가 데이터의 생성원리를 이해하고
그로부터 수학적인 관계를 유추하여 분포를 추론하는 것이 가장 바람직한 방법이라고 소개하셨다.
타이타닉 데이터를 다루다보면 굉장히 다양한 시대적, 상황적 고려를 통해서
데이터간의 상관관계를 밝혀내는 과정들을 볼 수 있는데 바로 이런 부분을 말씀하신거라고 본다.
아무튼 이런식의 히스토그램을 이용해 분포를 보고 모수를 추정하는 방법도 있지만
수학적으로 굉장히 중요한 정리인 중심극한정리를 이용하는 방법도 있다.
통계학적인 정보를 얻을 때 가장 중요한 정보는 바로 기대값이다.
대부분의 통계학적 범함수들은 이 기대값을 정의역으로 가지는 functional이므로
내가 얻은 데이터의 이상적인 총 집합인 모집단의 평균을 추정하는 작업은 굉장히 의미있다.
임의의 데이터공간 X 로 부터 추출된 n개의 데이터로 구성된 부분집합을 x 라고 하면
x를 계속해서 뽑아 x의 평균과 분산을 구할 수 있다.
우리가 이렇게 뽑은 임의의 x를 표본 이라고 하고 x의 평균을 표본평균 x의 분산을 표본분산이라고 한다.
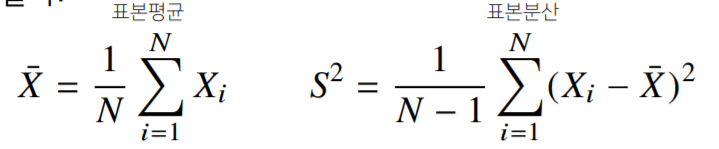
추출을 계속 할 수록 표본 평균의 기대값은 모평균에 근사하고
표본 분산의 기대값은 모분산에 근사하게 된다.
상세한 설명은 아래의 링크에 있다.
https://m.blog.naver.com/ao9364/222023124818
표본분산은 왜 n-1로 나눌까? : 자유도와 불편추정량 (feat. 표본평균의 평균과 분산 증명하기)
참고 이 포스트는 군소리는 최대한 배제하고 중요한 내용만 알차게 담기 위해 노력했으니 대충 앞부분만 읽...
blog.naver.com
특이한 점은 표본 분산을 구할때 총 확률변수의 수 보다 하나 작은 수로 나눠준다는 것인데
이것은 직관적으로 볼 때 임의의 표본의 분산은 모집단의 분산보다 작을 확률이 매우 높으므로
작은 쪽으로 편향되지 않은 좀 더 큰 값을 얻기 위함이라고 볼 수 있다.
이렇게 표본을 계속해서 추출하여 모집단이 따르는 정규분포의 모수를 추론하는 방식을 중심극한정리라고 한다.
// 최대가능도 추정법
최대가능도법은 이론적으로 가장 가능성이 높은 모수를 추정하는 방법이다.
가능도( likelihood )는 굉장히 이해하기 어려운 개념인데 conditional probability에 대한 이해가 부족한데로부터 함정에 빠진다.
최대가능도를 이해하기 전에 가능도부터 먼저 보자.
데이터공간 X에서 각 데이터 x_i가 독립적으로 추출될 경우 가능도는 아래와 같은데

저기서 확률 부분을 보면 conditional probability 로 되어 있다.
말로 풀어서 설명을 하면 어떤 \theta가 주저졌을때 x_i를 관측할 확률 이다.
그리고 그 모든 확률이 곱해져 있으므로 동시에 일어나는 일이 된다.
따라서 어떤 확률분포 모델이 \theta를 통해서 결정되면
결정된 모델의 분포에서 이산적으로 추출한 모든 데이터들이
데이터 공간 X에서 추출된 모든 x_i들과 일치할 확률을 구한 것이다.
그러므로 가능도 likelihood를 최대화하면 어떤 데이터 공간 X의 분포와
\theta를 통해 결정되는 모델의 분포를 일치시키는 결과를 가져오게 된다.
그러므로 아래의 식을 만족하는 \hat{\theta}_{MLE} 는 데이터 공간 X가 가지는 분포의 모수가 된다.
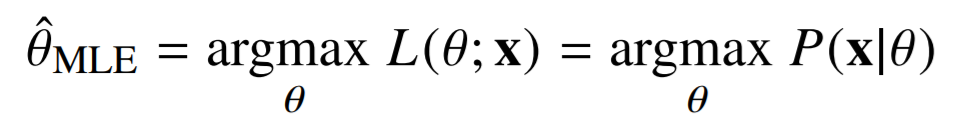
독립추출의 경우는 단조증가함수인 로그를 통해서 곱하기를 더하기로 바꿔주어 계산상의 이득을 볼 수 있다.
최대 가능도법은 역시 정규분포에서 많이 쓰는데
이때 가정이 매우 중요하다.
"만약 정규분포를 따르는 확률변수 X 로부터 얻은 독립적인 표본 {x_i | i = 1,2,3,...,n} 을 얻었을때"
라는 가정이 있어야 정규분포에서 maximum likelihood estimation 를 사용할 수 있게 된다.
위에서 분명히 \theta는 어떤 분포를 그릴 수 있는 모델의 변수라고 했고
이것은 어떤 분포의 모수임을 다르게 말한 것이다.
그러니까 정규분포의 MLE를 다시 쓰면
지금 우리가 가정한 모델은 정규분포를 따르고 거기에 모수를 \theta로 주어줄때
X로 부터 독립적으로 추출한 x_i들이 그 분포에 속할 확률을 최대한 높여봐라 하는 문제가 된다.
다시 더 간단하게 말하면
X가 정규분포를 따른다고 가정할때 그 분포의 모수를 구해라.
가 되는 것이다.
따라서 이 경우에 한해서 \theta는 \mu와 \sigma^2 이 된다.
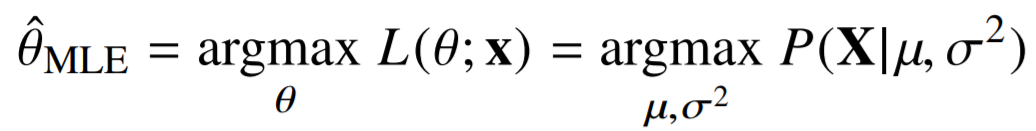
모든 최대가능도법이 이런 식을 따르는 것이 아님을 명심해야한다!
이것은 우리의 모델이 정규분포라는 것을 가정한 최대가능도법이다.
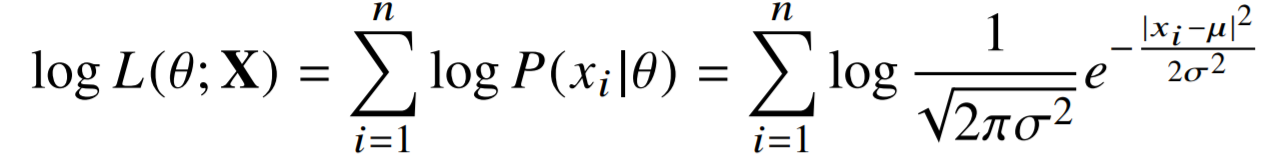

이렇게 Gaussian 분포를 이용해서 수식을 짜주고 log-likelihood로 바꿔주면 이런 식이 된다.
이 값을 최대로 만드는 모수는 얼마일까?
식을 보면 각 Gaussian 분포는 위로 볼록하고 로그함수는 단조증가하므로
미분하여 0이 되는 지점을 찾으면 최대값을 알 수 있다.
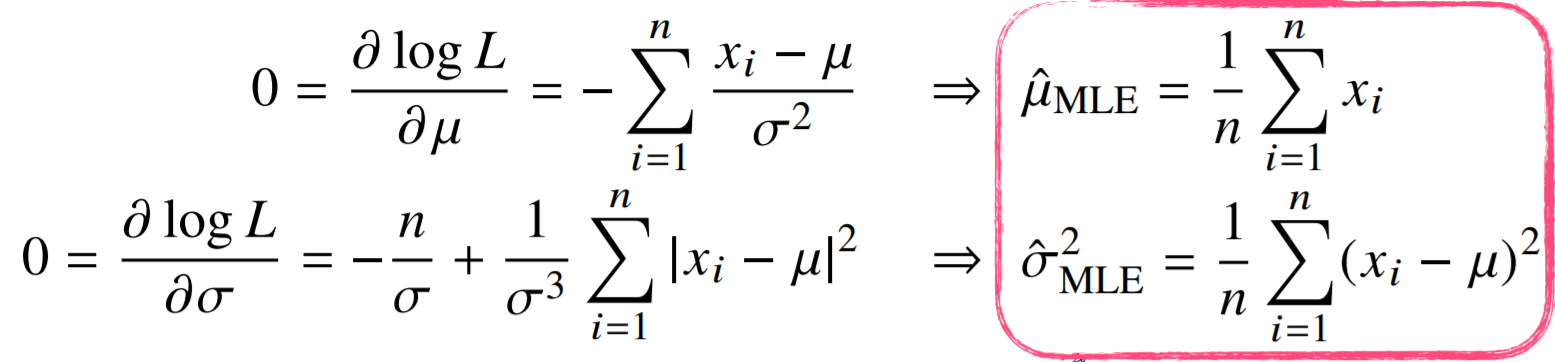
// 딥러닝의 모수 추정
모수 추정은 정규분포 뿐만 아니라 베르누이분포나 카테고리 분포에서도 사용할 수 있으나
수식 정리는 시간관계상 생략하도록 한다.
중요한 것은 딥러닝을 이용한 확률분포 예측인데
딥러닝의 output을 softmax함수로 사용하는 경우 우리는 확률을 예측한다고 볼 수 있다.
softmax 함수도 결국은 확률을 더욱 극명하게 하기위해 exp함수를 넣은 것일 뿐
그냥 확률에 불과하다.
그리고 그 확률을 결정한 분포는 딥러닝 모델 그 자체라고 할 수 있다.
예를 들어서 28*28의 모든 값을 싹 다 변화시켜가면서 우리가 학습한 MNIST분류기에 넣을 수 있다면
우리는 확률 분포를 그려볼 수 있겠지만 그건 사실상 불가능하고
기저가되는 면을 그릴 수도 없다.
그러므로 마치 Gaussian 분포의 수식을 보면 그 분포를 그리지 않고도 알듯
모델 자체가 어떤 분포를 의미한다고 보고 이 분포의 모양을 결정하는 모수를 모델의 변수인
weight와 bias 등으로 볼 수 있고 또 activation을 통해서 그 모수의 양이 변한다고 볼 수 있다.
그러므로 굉장히 많거나 때로는 그 수가 변하는 모수를 추정한 비모수 추정법이다.

여기서 목적함수를 cross-entropy로 쓰는 이유는 카테고리 분포의 최대가능도법을 공부하다보면 상세하게 나온다.
또 두 확률간의 거리를 정의하는 Kullnack-Leibler Divergence 를 이용해도 얻을 수 있다.
//베이즈 이론
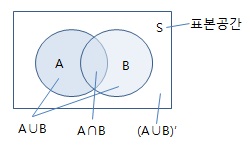
벤다이어그램을 통해서 A와 B가 일어날 확률을 보자.
A와 B의 교집합은 두가지 관점에서 볼 수 있다.
1. A 가 관측되면서 동시에 A가 주어졌을때 B가 관측될 확률
2. B 가 관측되면서 동시에 B가 주어졌을때 A가 관측될 확률
그러니까 1번은 A동그라미만 남기고 그 중에 B랑 겹친 부분을 보는 것이고
2번은 그 반대다.
이걸 수식으로 나타내면
$$P( A \cap B) = P(A|B)P(B) = P(B|A)P(A)$$
이렇다.
그러니까 정리하면
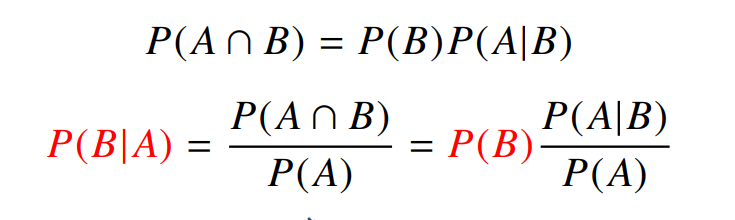
요렇게 된다.
이 부분에서 나는 가능도와 묶어서 이야기하는 것을 크게 좋아하지 않는데
몇몇 예제에서는 단순하게 conditional probability 로 이해하는 편이 훨씬 수월하기 때문이다.
특히 질병이나 불량품의 예시에서는 특히 더 그렇다.
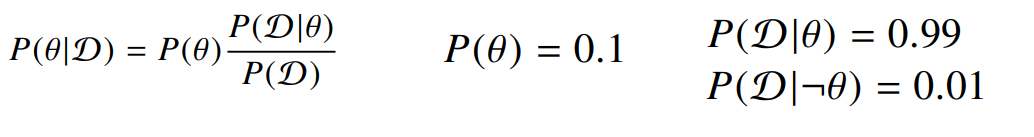
만약 질병 관련 예시를 든다면 D를 양성 판정, \theta를 실제감염 으로 이야기 하면 된다.
즉 병원체의 감염률은 0.1 이고
감염되었을때 양성 판정을 받을 확률은 0.99 이고
감염이 되지 않았으나 양성 판정을 받을 확률은 0.01 이 된다.

따라서 일단 이 검사를 받았을때 양성 판정을 받을 확률을 구할 수 있고

양성 판정을 받았을때 진짜로 감염되었을 확률을 이렇게 구할 수 있다.
여기서 사실 conditional probability 말고는 사용되지 않았는데 왜 저 부분을 likelihood 로 해석하는지는 아직 의문이다.
베이즈 정리의 중요한 점은 정보의 갱신이 가능하다는 점인데
이미 베이즈 정리를 통해서 정해진 조건부 확률 값을 새로운 사전 확률로 설정할 수 있다는 말이다.

이 확률은 실제로 계산해보면 굉장히 신뢰도가 낮은 검사여도
두번 혹은 세번을 거치면서 신뢰도가 상승하는 것을 볼 수 있다.
// 조건부 확률과 인과추론
통계의 가장 큰 맹점중에 하나는 인과관계과 상관관계를 오용할 수 있다는 점이다.
해적의 수가 감소하는 것과 해수면이 상승하는 것은 서로 상관관계가 있을 수 있으나 인과관계는 될 수 없다.
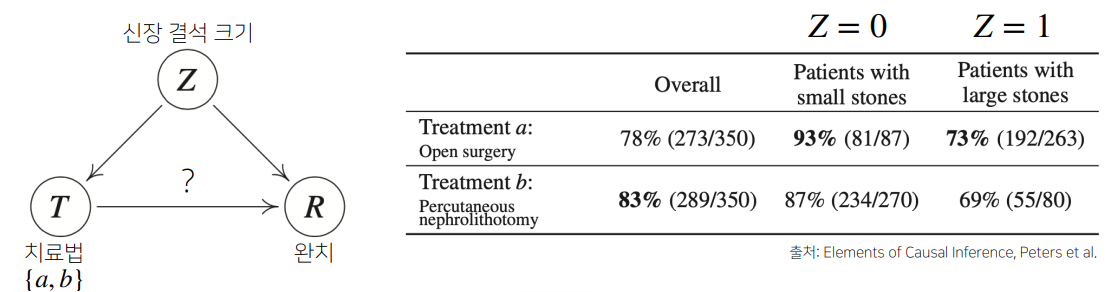
신장결석의 개복수술 결과를 보면 이런 맹점이 잘 드러나는데
신장결석의 크기라는 변수를 고려하지 않고 치료법의 결과만 놓고 보면
개복수술은 결과가 좋지 않은 치료법처럼 보인다.
하지만 이것은 결석의 크기라는 확률변수를 도입하는 순간 새롭게 해석된다.
즉 conditianal probability를 추정할때 적절한 condition을 모두 고려하지 않았기 때문에 생긴 오류다.
이런 경우에는 고려하지 않은 condition을 적절히 고려하여 evidence를 구하듯 처리해주면 오류를 수정할 수 있다.


끝
'딥러닝 머신러닝 데이터 분석 > BoostCampAITech' 카테고리의 다른 글
| [ Boost Camp ] Day-8 학습로그 (0) | 2021.08.10 |
|---|---|
| [ Boost Camp ] BPTT를 이해해 보자 (4) | 2021.08.09 |
| [ Boost Camp ] Day-4 학습로그 ( CNN, RNN ) (0) | 2021.08.06 |
| [ Boost Camp ] Day-2 학습로그( 신경망 학습 ) (0) | 2021.08.06 |
| [ Boost Camp ] Day-1 학습로그 (벡터, 행렬, 선형회귀, SGD) (0) | 2021.08.06 |




댓글