// 각 열에 따른 생존 확률
Survived는 살았을 경우 1, 죽었을 경우 0으로 표시된다.
이 점을 잘 생각하면 어떤 조건 하에서 전체 데이터의 mean 값을 구하면
전체 데이터의 수로 생존자의 수를 나눈 값이 된다.
이 값은 단순히 mean 값이 아니고 생존율이 된다.
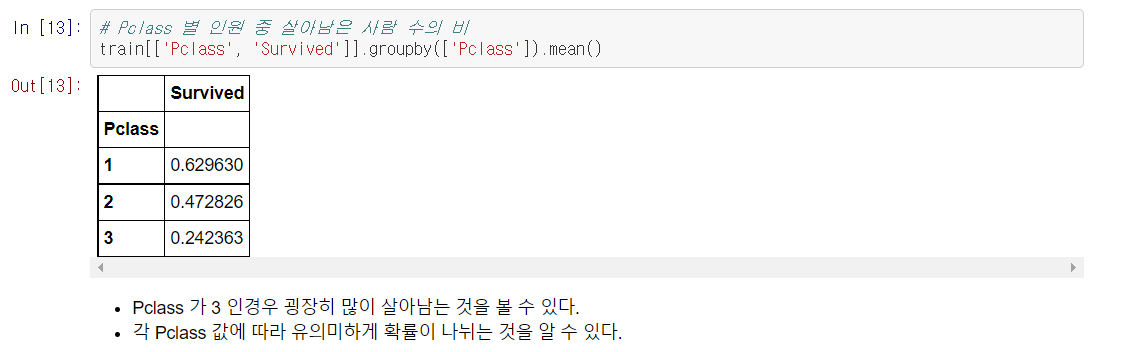


이 과정에서 원문 작성자가 중요하게 보는 부분은 바로 "확률이 서로 유의미하게 다른 분류"를 찾아내는 작업이었다.
그러니까 정말 이 카테고리의 값이 더 높거나 더 낮으면 생존확률이 더 높아지던지 낮아지던지 하는가 하는 것이다.
유의미한 correlation을 본 것이라고 생각할 수도 있는데 사실 나도 여기서는 좀 의아했던 것이
단순히 correlation을 본 것이 아니라 구분 가능한 기준으로 확률이 분배되는지를 확인하는 작업이라고 읽혀졌다.
이런 경우가 아주 없는 건 아니고 그런 경우 one-hot encoding을 해서 차원을 나눠주기 마련인데
그렇게 하지 않아서 좀 의아하긴 했다. 아무튼 일단 따라해보는데 의미를 두고 있으므로 일단 따라가 보자.

Ticket은 결측치가 많아서 버린게 아니라 중복되는 값이 많고 그게 분석에 유리하게 작용하지 않아서 버린 것이다.
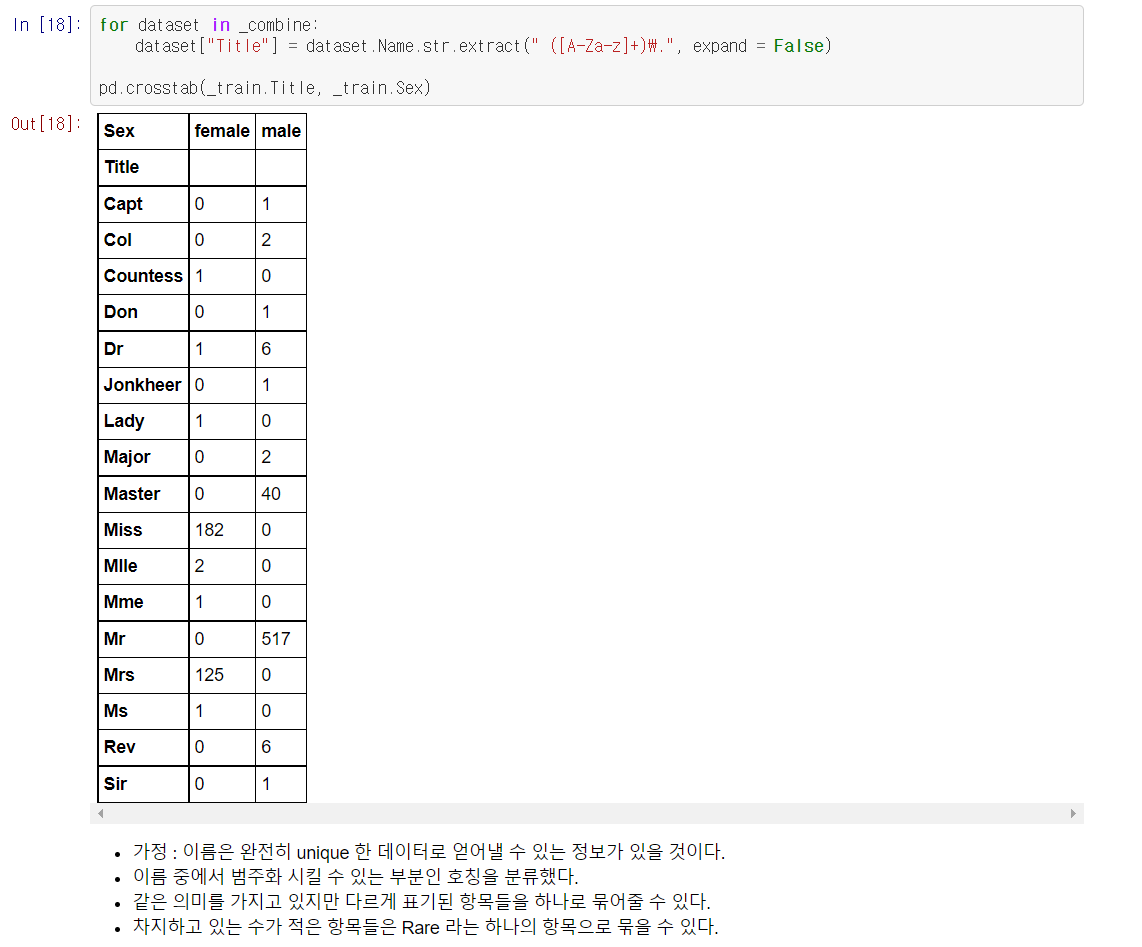
여기서는 regex 즉 정규표현식을 이용해서 이름의 Title을 뽑아냈다.
regex를 사용할 수 있는가 혹은 원하는 문자열을 자유롭게 핸들링 할 수 있는가 하는 문제는 아주아주 단골문제다.
regex의 경우는 익힐 수 있는 기회가 올때마다 확실하게 익혀두는게 좋다.
crosstab을 이용해서 서로 다른 두개의 열 간에 unique들의 count를 표시했다.
완벽하게 unique 한 이름 데이터는 사실 아무런 쓸모가 없다는 의미를 내포하고있다.
생존확률과 아무런 correlation을 가지지 않는다는 뜻이다.
그러면 우리는 여기에서 어떤 의미를 가질 수있는 범주를 찾아서 범주화시키는 작업을 해야한다.
호칭을 알고 있으면 성별과 사회적 지위를 동시에 알 수 있으므로 Title이라는 새로운 열에 뽑아서 저장했다.
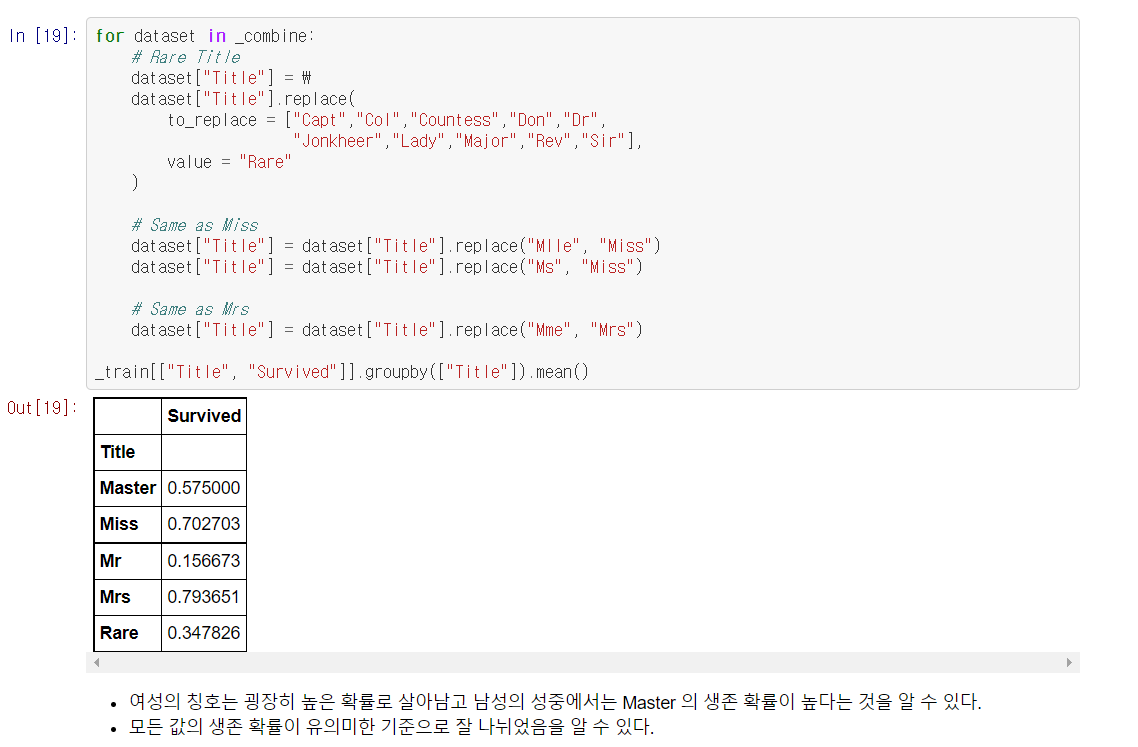
판단한 근거를 토대로 범주를 정리해준다.
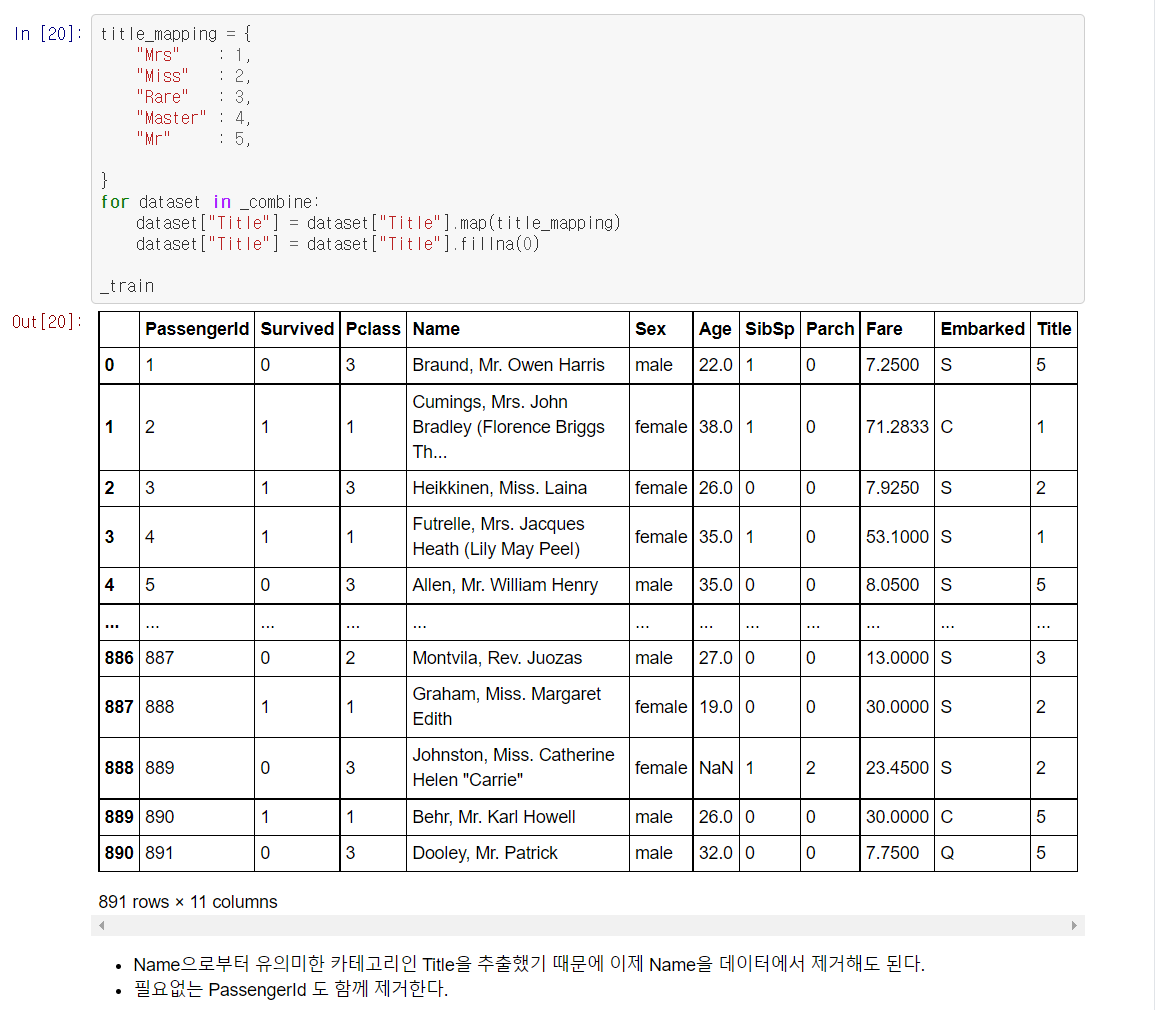
컴퓨터가 연산할 수 있도록 숫자로 바꿔주는 작업도 빼먹지 않아야한다.
이제 Embarked 를 제외한 모든 유의미한 정보가 숫자로 변환되어 남아있다.
이 다음에서는 결측치에 관한 접근으로 어떤 근거에 의한 추산을 진행할 것인지 알아보도록 하자.
코드는 내 깃헙에 모두 올라가 있다.
hyun06000/ML_Pythion_TitanicWithPandasAndTensorflow
Contribute to hyun06000/ML_Pythion_TitanicWithPandasAndTensorflow development by creating an account on GitHub.
github.com
'딥러닝 머신러닝 데이터 분석 > TitanicWithPandas' 카테고리의 다른 글
| [ Pandas ] 데이터 분석을 통한 Titanic 생존자 예측 - 1 (0) | 2021.07.14 |
|---|

댓글