// 타이타닉?
타이타닉은 이제 잘 모르는 세대가 생겼을 것같은데
일단은 엄청 큰 여객선의 이름이다.
이 배는 당시의 하이테크놀러지를 모두 적용하여
'절대 침몰하지 않는 배'라는 믿음이 있었다.
물론 당연히 침몰했다.
그러니까 생존자 데이터를 분석하는 거고...
아무튼 영화로도 나올 만큼 엄청난 규모의 세계적인 이슈였고
무엇보다 큰 인명피해를 동반한 끔찍한 사고였다.
이 배가 출항할때 탑승자들의 이름과 신상등을 적어둔 기록이 있는데
배가 큰 만큼 이 기록이 분석 가능할 정도의 규모가 되고
사회의 각 계층이 탑승하면서 다양한 데이터가 만들어졌다.
그래서 우리는 이 배에 탑승한 사람들의 데이터들이 가지는 연관성으로부터
이 사람이 살았는 지 죽었는지 분석할 수 있어 데이터 분석의 입문으로 굉장히 많이 사용되고 있다.
// 들어가기전에
우선 이 데이터는 Kaggle 기준임을 밝히고
분석에 있어 딥러닝은 하나도 쓰지 않는 다는 것을 알린다.
딥러닝을 쓸 수 있는 방법도 분명히 있겠지만 여기서는 딥러닝을 제외한 머신러닝 기법들을 사용할 것이다.
시도해본 결과 이런 식의 정형 데이터는 비정형데이터에 비해 딥러닝이 잘 확약하지 못한다.
그냥 내 경험이나 참고만 할 것.
아무튼
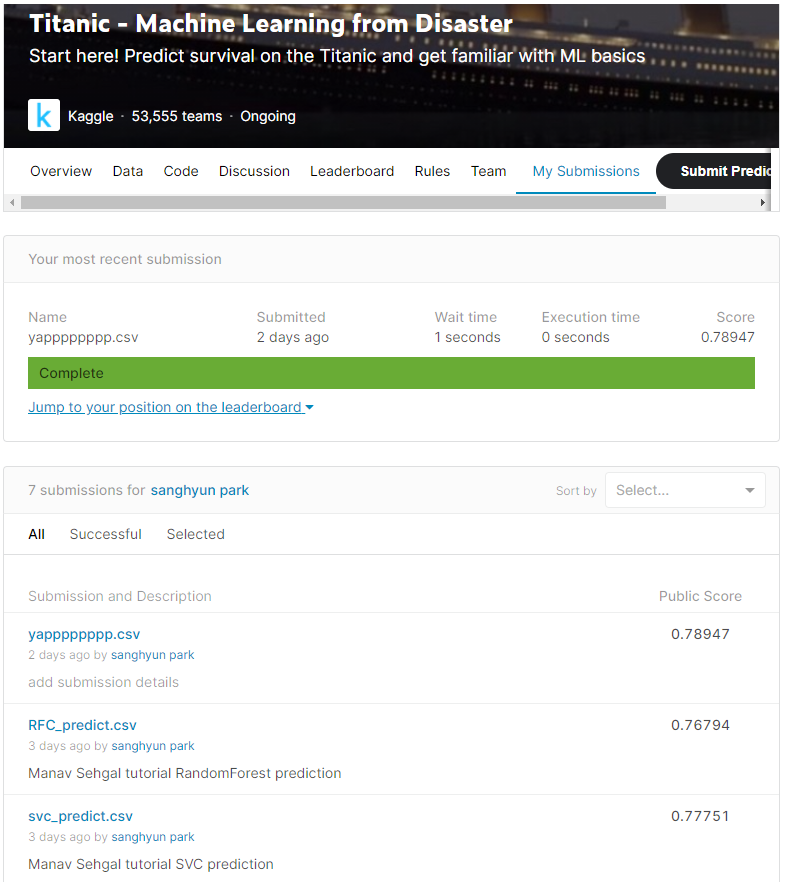
이렇게 78.9% 정도의 정확도를 Testset에서 보이고 있는 방식을 설명하겠다.
더 높은 정확도가 필요한 사람들은 더 좋은 자료들이 많이 있으니 그 자료들을 보길 바란다.
그리고
https://www.kaggle.com/startupsci/titanic-data-science-solutions
Titanic Data Science Solutions
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
이분의 설명을 따라서 진행하는 것임을 밝힌다.
// 데이터 분석
캐글에서 타이타닉 데이터를 받을 수 있으니 다운받아주고 판다스를 통해서 불러온다.
필요한 패키지를 모두 불러오고 데이터도 불러왔다.
훈련 데이터를 분석하여 얻어낸 정보를
훈련데이터와 학습데이터 모두에게 동시에 적용해주어야하는 경우가 있으므로
편의를 위해서 둘을 하나의 리스트에 담아준다.
이때 읽어들인 파일들은 데이터프레임(pd.DataFrame) 이라는 클래스로 되어있다.
// 데이터 들여다보기
맨처음 할 일은 이 데이터를 직접 보는 것이다.
주어진 데이터를 잘 볼 수 있는 눈이 있어야만 그 다음 작업을 수월하게 진행할 수 있다.
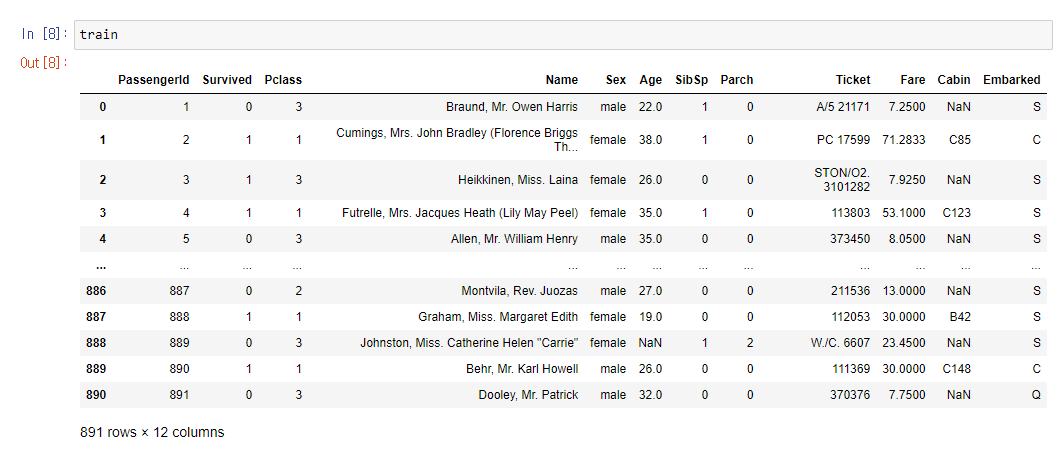
그냥 데이터를 불러와서 출력해보면 이렇다.
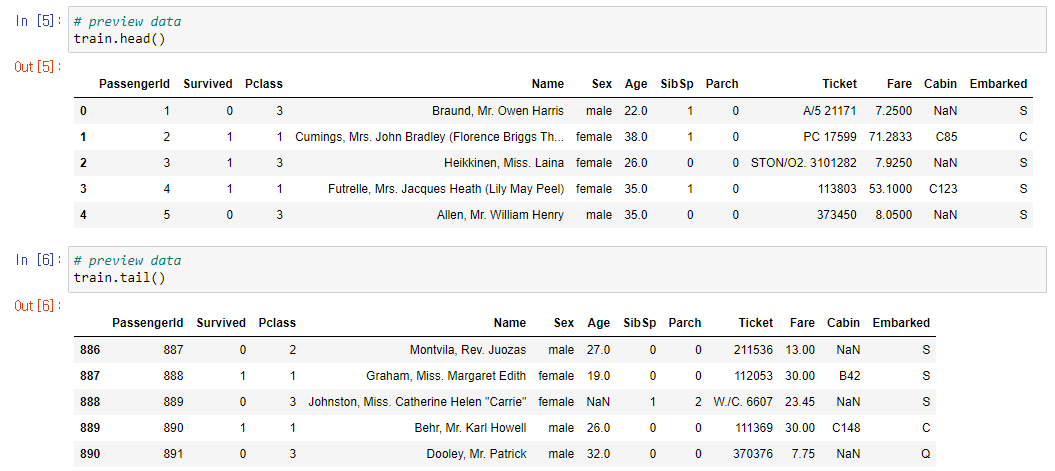
.head() 와 .tail() 메소드를 통해 가장 앞쪽 끝과 가장 뒷쪽 끝을 출력해 볼 수 있다.
데이터가 아주 많아서 출력에 시간이 오래걸리는 경우 유용하게 사용 가능하다.

이런식으로 .columns를 불러온 후 .values 를 이용해서 값들을 리스트 형식으로 받는 것도 가능하다.
문제에 따라 이런 열 이름을 알려주는 경우도 알려주지 않는 경우도 있다.
예컨데 SibSp 과 Parch 는 각각 Siblings-Spouses 와 Parants-Children 의 약자다.
이런 식으로 알려줄 수도 있지만 어떤 내용의 숫자인지 알려주지 않는 경우도 있다.
쭉 보면 살아있는지 죽었는지 0과 1로 표시가 되어있고
몇 등급의 선실을 받았는지 알 수 있으며 이름과 성별, 동승자의 수 등등을 알 수 있다.
그런데 Cabin 과 Age 를 보면 Nan 이라고 적힌 칸이 보인다.
이 칸은 말그대로 빈칸이고 아무런 정보가 없는 칸이다.
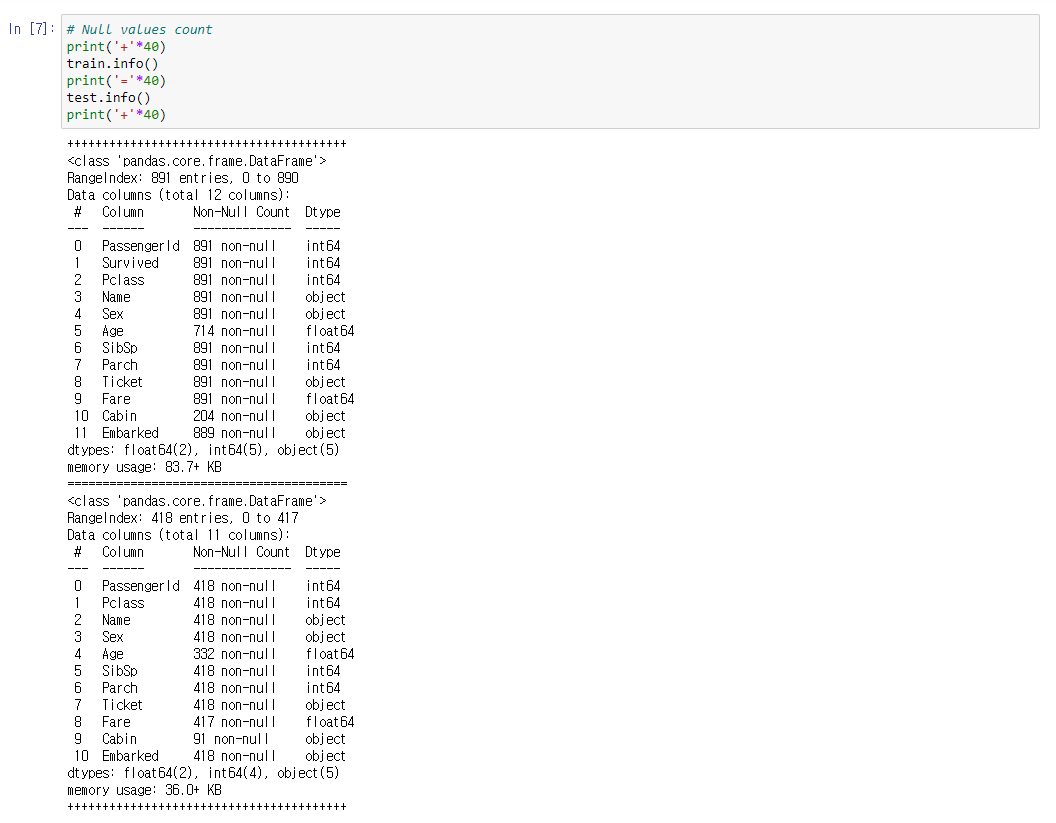
.info() 메소드를 이용하면 해당 열이 몇개의 채워진 칸을 가지는지
데이터의 타입은 어떤것인지 한눈에 알 수 있게 보여준다.
이를 근거로 하여 결측률이 너무 높은 데이터는 버리고 작업한다던지
결측치를 적절한 근거를 토대로 채워넣는 전략을 취한다던지 하는 계획을 세울 수 있다.
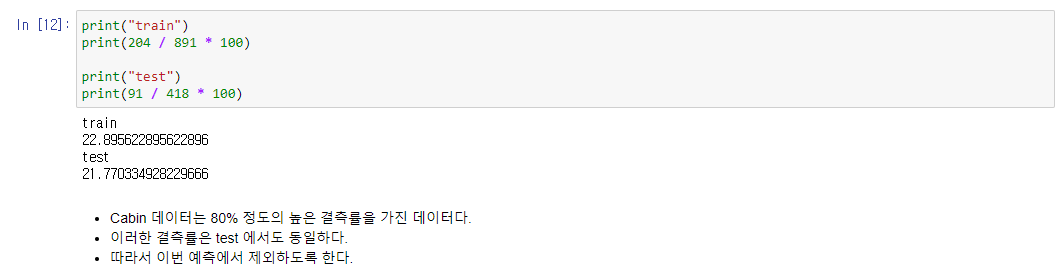
마크다운으로 작성한 설명처럼 Cabin의 경우는 결측률이 너무 높기때문에 사용할 수 없는 데이터라고 판단하였다.
이 번 분석에서는 이 Cabin 항목 없이 분석을 진행한다.
반면 Age의 경우 어느 정도 관계가 있는 데이터를 분석하여 채워 넣는 것이 가능할 것이므로
어떻게 채워 넣을지 전략을 잘 구상해야한다.
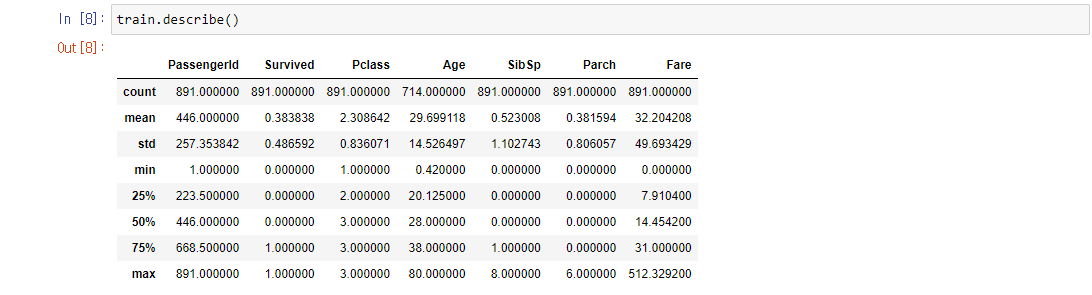
.describe() 메소드를 이용하여 이 데이터의 통계적인 개요를 한눈에 보는 것도 가능하다.
그런데 숫자 데이터가 아닌 열들은 동일한 통계, 예를 들면 min max등을 적용할 수 없으므로
따로 묶어서 보아야한다.

.info()에서 보았듯 이 열들은 object 타입을 사용하므로 object 들만 따로 뽑아서 보면 볼 수 있다.
이름과 티켓을 눈여겨볼 수 있는데 이름은 891명이 모두 서로 다른 이름을 사용하여
unique 와 count 가 동일한 값을 가지는 것을 볼 수 있는 반면
티켓의 경우는 중복되는 티켓이 여러 사람에게 동시에 발행된 것을 알 수 있다.
이 부분에 대하여 "가족단위로 동일한 티켓을 발행했을 것이다" 라는 추론을 해볼 수도 있겠다.
하지만 이 부분이 확실한지는 알 수 없으므로 티켓으로부터 유의미한 통계를 얻기는 힘들다고 보도록 한다.

이런식으로 보면 얼마나 중복된 값이 존재하는지 수치로 보여줄 수 있고
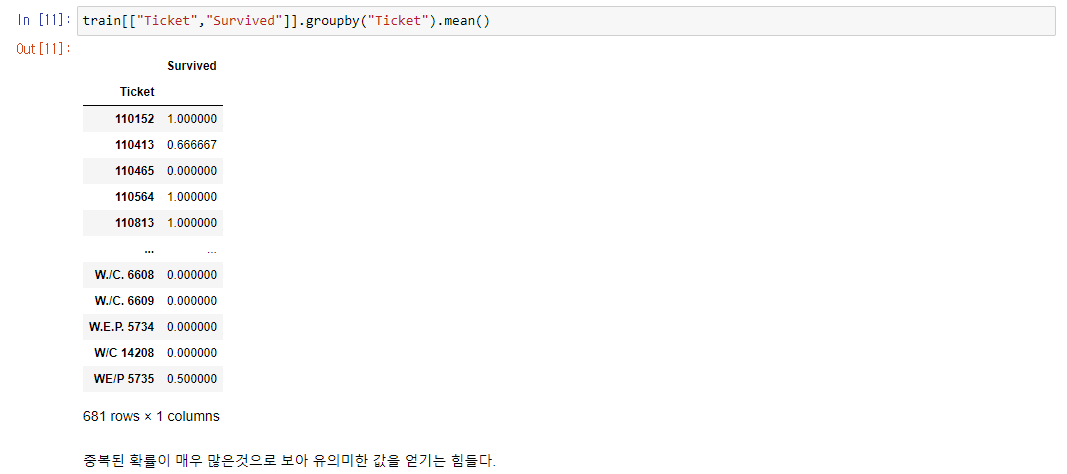
하나의 티켓이 반드시 동일한 생존여부를 결정하는 것이 아니기 때문에
즉 같은 티켓을 소지했다고 해도 생존 여부는 달라질 수 있기때문에
티켓과 생존여부는 직접적인 연관이 없다고 할 수 있다.
위의 코드에서 사용된 메소드는 조금 후에 설명하도록 한다.
물론 티켓을 통해서 가족임을 알아내고 그중에서 부모와 자녀관계 등을 따져서
자녀의 나이대와 부모의 나이대를 추산하는 등의 작업등을 하는 것이 가능하지만
여기서는 빠른 문제해결을 위해서 그냥 버리도록 한다.
2번 글에서 각 feature 별 통계적인 지표들을 비교하여 분석전략을 짜는 것을 설명하도록 하겠다.
'딥러닝 머신러닝 데이터 분석 > TitanicWithPandas' 카테고리의 다른 글
| [ Pandas ] 데이터 분석을 통한 Titanic 생존자 예측 - 2 (0) | 2021.07.19 |
|---|

댓글