지난 글에서 jetson nano를 워커노드로 세팅하는 방법까지 알아봤다.
k8s 시리즈는 계속해서 연재중이라 마스터 노드를 설치하는 방법부터 여기까지 와있다.
젯슨 아키텍쳐 때문에 정말이지 설정을 찾아내는게 힘들었다.
진짜 진짜 힘들었다....
그래도 한번 잘 정리를 해서 남겨보자.
젯슨 구형으로 진행한 점을 미리 알린다.
우선은 젯슨을 초기화 할 때 GUI를 쓰기 때문에 OS를 플레시 한 후에
처음은 반드시 모니터와 키보드 마우스를 모두 연결해야 한다.
그리고 첫번째 로그인을 해 준다.
이제는 우리에게 GUI가 필요 없다.
sudo systemctl set-default multi-user
sudo reboot멀티 유저 모드로 전환하고 재부팅 해준다.
그러면 초기 세팅은 끝이다.
https://github.com/jugfk/jetson-fan-ctl
GitHub - jugfk/jetson-fan-ctl: 젯슨나노를 위한 오토매직 냉각팬 제어
젯슨나노를 위한 오토매직 냉각팬 제어. Contribute to jugfk/jetson-fan-ctl development by creating an account on GitHub.
github.com
위의 저장소에서 fanctl을 받고 실행해 준다.
물론 쿨링팬이 있어야 한다.
이제는 시스템을 한번 업데이트 해 줘야 한다.
우분투 리눅스의 패키지 관리자인 apt를 이용해서 업데이트 해 준다.
여기서 약간의 추측인데 Jetson의 GPU 가속화는 jetpack 이라는 전용 소프트웨어를 이용해서 진행된다.
그리고 이 jetpack을 이용할 수 있는 도커 이미지들도 따로 제공되고 있다.
그런데 이 이미지들의 gpu 사용관련 라이브러리들이 호스트와 공유되는 양상을 보인다.
원래는 격리된 도커 컨테이너 안에서 호스트와는 별개의 라이브러리들을 사용할 수 있는게 일반적인 반면
jetpack을 위한 이미지들은 경량화 때문인지 호스트의 버전이 달라지면 컨테이너 내부에서도 영향을 크게 받는다.
따라서 처음 제공된 라이브러리들 이외에 일반적인 우분투를 위해서 제공하는 라이브러리들의 경우
별도의 작업으로 설치하면 안된다.
이 점에 유의하면서 기존의 라이브러리들을 모두 업그레이드 해 주자.
sudo apt update && sudo apt upgrade업그레이드 중간에 상호작용해야하는 부분이 있으므로 Y 같은 것들을 잘 눌러주자.
어마어마한 양의 업그레이드를 마치고 확실한 설정 변경을 위해 리부트를 한번 해 준다.
이제 마스터 노드에 연결하기 위해 k3s를 깔아준다.
여기서 정말정말정말 중요한 부분이 바로 런타임인데
내가 이전에
2023.08.17 - [Backend MLOps/On-premise setting] - [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 1
[k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 1
최근 흥미로운 주제가 생겨서 이 시리즈를 적어 본다. 싱글 노드 쿠버네티스를 구성하는 방법은 여러가지가 있다. 쿠버네티스 연습이 필요한 경우 혹은 회사에서 쿠버네티스 환경을 구축해야하
davi06000.tistory.com
이 글에서도 언급한 바 있지만 쿠버네티스는 다양한 런타임을 쓸 수 있고
특히 k3s의 경우 containerd를 디폴트 런타임으로 쓴다.
따라서 nvidia-docker를 쓰려면 이 런타임을 도커로 바꿔서 설치해야 한다.
2023.09.24 - [Backend MLOps/On-premise setting] - [k8s] Jetson Nano에 k3s 설치하고 워커노드로 구축하기
[k8s] Jetson Nano에 k3s 설치하고 워커노드로 구축하기
운이 좋게도 당근으로 젯슨 두대를 구했다. 젯슨의 기본적인 세팅은 간략하게 설명하고 넘어가겠다. 우선 젯슨은 ARM아키텍쳐기 때문에 역시 전용 OS를 사용하고 이 OS는 기본적으로 우분투 데스
davi06000.tistory.com
https://docs.k3s.io/advanced#using-docker-as-the-container-runtime
Advanced Options / Configuration | K3s
This section contains advanced information describing the different ways you can run and manage K3s, as well as steps necessary to prepare the host OS for K3s use.
docs.k3s.io
위의 글과 공식문서를 참고하여
curl -sfL https://get.k3s.io | K3S_URL=https://${YOUR_SERVER_NODE_IP}:6443 K3S_TOKEN=${YOUR_NODE_TOKEN} sh -s - --docker설치 부분의 명령어를 아래와 같이 바꿔준다.
이제 마스터노드에서 확인하면

잘 등록되었다.
그리고 젯슨에서도 도커를 통해 컨테이너들을 확인할 수 있는지 보면

쿠버네티스를 위해 떠있는 컨테이너들을 확인할 수 있다.
이제 nvidia docker runtime을 디폴트로 설정해 준다.
sudo vim /etc/docker/daemon.json
# {
# "default-runtime": "nvidia",
# "runtimes": {
# "nvidia": {
# "path": "nvidia-container-runtime",
# "runtimeArgs": []
# }
# }
# }
이러면 거의 끝났다.
이미 젯슨에서는 도커 컨테이너 런타임을 통해서 GPU를 쓸 수 있게 설정되어 있으므로
추가적인 런타임을 설치하거나 설정을 바꿔버리면 바로 망한다.
이제 kubeflow MPI operator를 설치해 주고
https://github.com/kubeflow/mpi-operator
GitHub - kubeflow/mpi-operator: Kubernetes Operator for MPI-based applications (distributed training, HPC, etc.)
Kubernetes Operator for MPI-based applications (distributed training, HPC, etc.) - GitHub - kubeflow/mpi-operator: Kubernetes Operator for MPI-based applications (distributed training, HPC, etc.)
github.com
다음과 같은 예제 파일을 만든다.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import horovod.torch as hvd
hvd.init()
torch.manual_seed(0)
if torch.cuda.is_available():
torch.cuda.set_device(hvd.local_rank())
transform = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
]
)
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=hvd.size(),
rank=hvd.rank()
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=32,
sampler=train_sampler
)
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc = nn.Linear(28*28, 10)
def forward(self, x):
x = x.view(-1, 28*28)
return self.fc(x)
model = SimpleNet()
if torch.cuda.is_available():
model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
optimizer = hvd.DistributedOptimizer(
optimizer,
named_parameters=model.named_parameters()
)
for epoch in range(50):
for i, (inputs, labels) in enumerate(train_loader):
if torch.cuda.is_available():
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
최고 간단하게 짤 수 있는 horovod를 이용한 MNIST 훈련이다.
그리고 이 스크립트를 돌릴 수 있게 도커 이미지를 만든다.
FROM nvcr.io/nvidia/l4t-pytorch:r32.6.1-pth1.8-py3
RUN mkdir -p /run/sshd
RUN apt-get update \
&& apt-get install -y \
openssh-server \
apt-utils \
libffi-dev \
libopenmpi-dev \
openmpi-bin
RUN ln -sf $(which pip3) /usr/local/bin/pip
RUN pip install pip --upgrade && pip install cmake
RUN HOROVOD_WITHOUT_TENSORFLOW=1 \
HOROVOD_WITH_PYTORCH=1 \
HOROVOD_CPU_OPERATIONS=MPI \
HOROVOD_WITH_MPI=1 \
HOROVOD_WITHOUT_MXNET=1 \
CUDACXX=/usr/local/cuda-10.1/bin/nvcc \
pip3 install horovod
RUN sed -i 's/[ #]\(.*StrictHostKeyChecking \).*/ \1no/g' /etc/ssh/ssh_config && \
echo " UserKnownHostsFile /dev/null" >> /etc/ssh/ssh_config && \
sed -i 's/#\(StrictModes \).*/\1no/g' /etc/ssh/sshd_config
COPY ./train_script.py /app/train_script.py
WORKDIR /app
하나하나 설명하자면
ssh로 통신하는 MPI의 특성상 ssh가 양방향으로 깔려있고 서로 비밀번호 없이 통신할 수 있는 상태여야 한다.
이를 위해 필요한 라이브러리들을 깔아주고 openmpi도 깔아준다.
그리고 적절한 환경변수들을 찾아내서 horovod를 설치해 준다. (공식문서 참고)
그리고 가장 중요한 부분인데 ssh의 상호검증 부분을 건너뛰도록 설정을 바꿔준다.
컨테이너들간에 적절한 키들을 직접 줄 수도 있지만 이 방법이 훨씬 간단하다. (물론 보안은 낮아진다.)
그리고 아래와 같은 yaml파일을 만들어서 배포한다.
apiVersion: kubeflow.org/v2beta1
kind: MPIJob
metadata:
namespace: jetson-horovod
name: horovod-mpi-job
spec:
slotsPerWorker: 1
runPolicy:
cleanPodPolicy: Running
sshAuthMountPath: /root/.ssh
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- name: horovod-container
image: docker.io/hyun06000/jetson-horovod:latest
command:
- mpirun
args:
- -np
- "2"
- --allow-run-as-root
- -bind-to
- none
- -map-by
- slot
- -x
- LD_LIBRARY_PATH
- -x
- PATH
- -mca
- pml
- ob1
- -mca
- btl
- ^openib
- python3
- /app/train_script.py
Worker:
replicas: 2
template:
spec:
containers:
- name: horovod-container
image: docker.io/hyun06000/jetson-horovod:latest런쳐의 경우 gpu를 사용하지 않고 메니징만 하는 것으로 보인다.
진짜인지는 좀 더 연구가 필요하다.
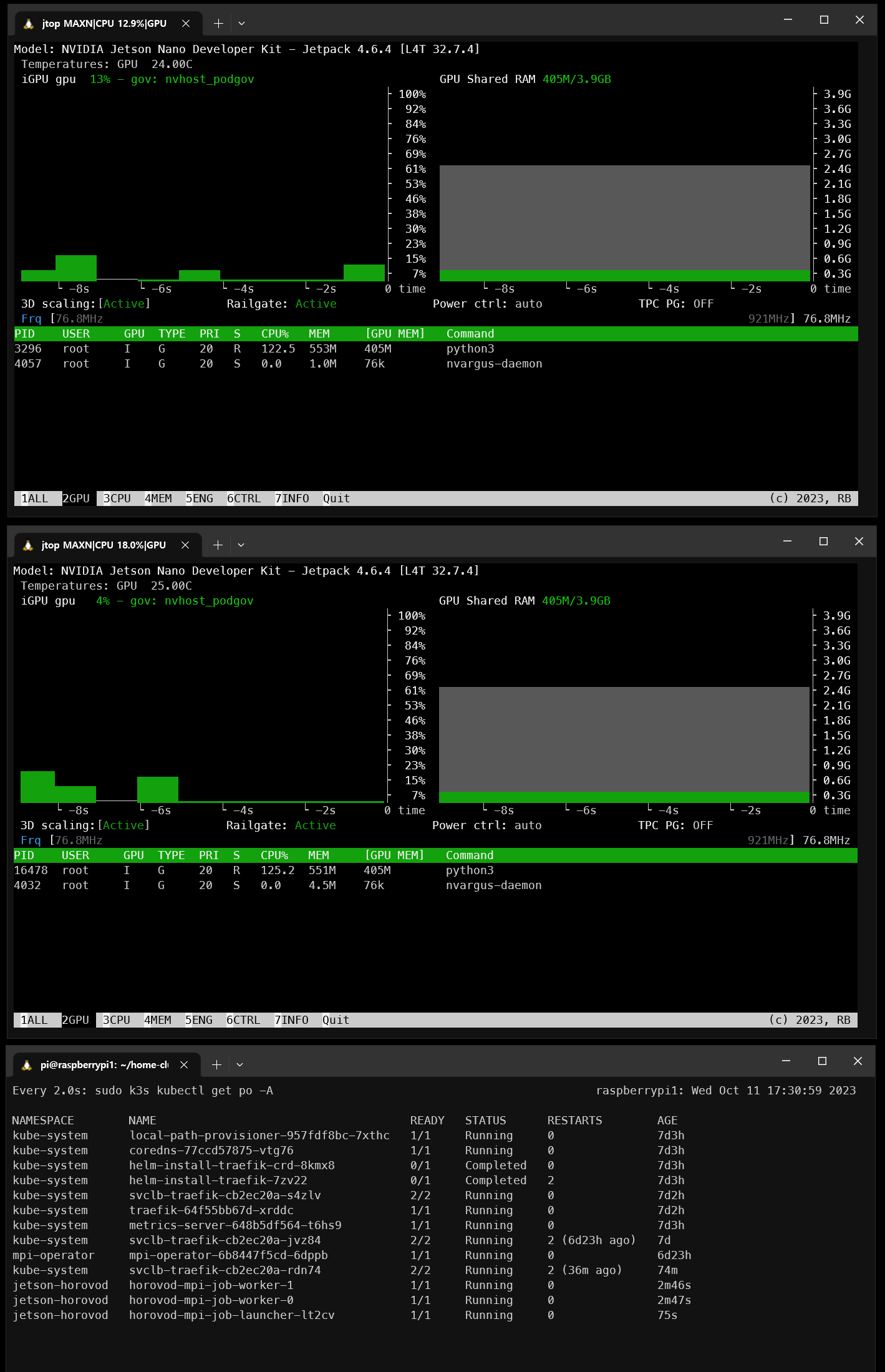
워커의 레플리카를 2로 만들어 주고 np 를 2로 주면 2대 모두 돌아간다.
가끔 Running에서 멈출때가 있는데 이럴때는 서비스가 생성되는것 보다 먼저 런쳐가 생성된 경우일 확률이 높다.
런쳐 파드의 로그를 찍고 통신 문제면 런처만 다시 시작해 준다.
생각보다 gpu를 많이 잡아 먹지 않는다.
'Backend MLOps > On-premise setting' 카테고리의 다른 글
| [k8s] Jetson Nano에 k3s 설치하고 워커노드로 구축하기 (0) | 2023.09.24 |
|---|---|
| [MPI] 파이썬으로 멀티노드 분산컴퓨팅 처리 - 2 (0) | 2023.09.12 |
| [MPI] 파이썬으로 멀티노드 분산컴퓨팅 처리 (0) | 2023.09.12 |
| [MPI] 멀티노드로 병렬연산, 분산컴퓨팅 처리하기 (0) | 2023.09.03 |
| [k8s] NFS 기반 PersistentVolume 직접 구축하기 - 2 (0) | 2023.09.02 |




댓글