이 글은 아래의 글들에 의존성을 가진다.
2023.08.17 - [Backend MLOps/On-premise setting] - [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 1
2023.08.23 - [Backend MLOps/On-premise setting] - [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 2
[k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 2
지난번 글에서 kubeadm을 설치하고 containerd, docker 같은 런타임을 이용해서 클러스터를 구성하는 과정을 진행해 보았다. 2023.08.17 - [Backend MLOps/On-premise setting] - [k8s] kubeadm 을 이용해서 싱글노드 쿠버
davi06000.tistory.com
[k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 1
최근 흥미로운 주제가 생겨서 이 시리즈를 적어 본다. 싱글 노드 쿠버네티스를 구성하는 방법은 여러가지가 있다. 쿠버네티스 연습이 필요한 경우 혹은 회사에서 쿠버네티스 환경을 구축해야하
davi06000.tistory.com
쿠버네티스의 가장 좋은 예제는 모니터링을 구현해 보는 것이라고 생각한다.
모니터링 시스템은 대충 이런식으로 형성된다.
1. 원하는 정보를 취합해서 제공해주는 백엔드 서버인 exporter를 띄운다.
2. 주기적으로 exporter에 요청을 날려 정보를 수집하는 prometheus를 띄운다.
3. prometheus에 저장되어 있는 정보를 시각화해주는 grafana를 띄운다.
4. 최종적으로 외부 접근이 가능한지 네트워크를 확인한다.
이 순서로 가보자.
우선 쿠버네티스는 상태를 정의하는 것이 핵심이다.
즉 "이런 이런 상태를 유지해라" 라는 명령을 잘 내려야 한다.
그 상태를 자세하게 기록하는 방식이 yaml 파일을 작성하는 것이다.
1. exporter pod
apiVersion: v1 # 소통을 위한 API 버전 정의
kind: Pod # k in d 가 아니라 카인드. 띄울 리소스의 종류
metadata: # 리소스 내부 구성요소가 아니라 메타데이터를 정의
name: node-exporter # 띄울 파드의 이름
namespace: monitoring # 파드가 띄워질 네임스페이스
labels: # 파드를 식별하기 위한 레이블 정의
app: node-exporter
spec: # 파드 내부 사양 정의
containers: # 파드로 묶여서 띄워질 컨테이너들 목록
- name: node-exporter # 컨테이너 이름
image: # 컨테이너 이미지
prom/node-exporter:latest
ports: # 컨테이너가 통신할때 사용할 포트들
- name: exporter-port # 리스닝할 포트의 이름
containerPort: 9100 # 리스닝할 포트의 번호
hostNetwork: true
hostPID: true리눅스 시스템 모니터링에 많이 쓰이는 노드 익스포터를 설치하는 부분이다.
저렇게 내가 유지하고 싶은 `상태` 를 기술해주면 저 상태를 유지하기 위해서
kubelet이 열심히 일하면서 이미지도 받고 컨테이너도 올리고 네트워크도 관리하고 그런다.
우리는 저걸 알려만 주면 된다.
그런데 싱글노드에서는 이걸 Pod로 띄워도 상관없지만
멀티노드에서는 이런 시스템 모니터링의 경우
모든 노드에 동일하게 적용되도록 상태를 지정해야 모든 노드의 시스템을 볼 수 있다.
그런 경우 데몬셋을 사용한다.
apiVersion: apps/v1 # DaemonSet을 쓰기 위한 API 버전
kind: DaemonSet # 리소스 종류
metadata: # 리소스 메타데이터
name: example-daemonset # DaemonSet의 이름
namespace: monitoring # DaemonSet이 뜰 네임스페이스
spec:
selector: # 이 DaemonSet이 관리할 파드 식별자
matchLabels:
app: monitoring-app # 키 값 "app", 벨류 값"monitoring-app"
template: # 관리할 파드의 템플릿
metadata: # DaemonSet은 모든 노드를 관리하면서 이 템플릿에 해당하는 파드가 있는지 감시하고 생성함
labels:
app: monitoring-app # 파드식 별자. 이걸 보고 데몬셋이 관리할지 말지 결정함
spec: # 파드 세부 스펙
containers:
- name: node-exporter
image: prom/node-exporter:latest
ports:
- name: exporter-port
containerPort: 9100
이제 배포해보자.

kubectl create namespace monitoring
kubectl apply -f .저렇게 디렉토리를 나눠서 yaml파일을 모아두면 특정 디렉토리 아래의 모든 파일을 한번에 배포할 수 있는데...
이게 진짜 나중에 귀찮아 지기 때문에 잘 나눠둬야한다.

잘 떴다.
이제 어떻게 확인을 하느냐,
프로메테우스로 바로 연결해도 되지만 여기서는 약간의 과정을 더 하자.
저 파드의 결과를 볼 수 있도록 네트워크를 약간 설정해줘야 한다.
파드가 네트워킹을 할 수 있게 해주는 리소스를 서비스라고 하는데
아래와 같이 설정할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: node-exporter-service
namespace: monitoring
spec:
selector:
app: node-exporter # 노드 익스포터 파드를 식별하기 위한 셀렉터
ports:
- name: exporter-port
protocol: TCP
port: 9100 # 클러스터 ip에 바인딩되는 포트
targetPort: 9100 # 파드의 실재 어플리케이션이 리스닝하는 포트
type: NodePort # 서비스 유형, NodePort형태로 지정

이미 배포된 데몬셋은 변화가 없고
서비스만 배포된 것을 알 수 있다.

잘 떠있다.
이제 해당 포트로 접속해보자

잘 된다.
저기 메트릭을 눌러보면 상세한 메트릭들을 볼 수 있다.
2. 프로메테우스
이런 방식으로 메트릭을 `볼` 수 있다.
그러면 그걸 수집해서 저장하고 그 과정을 주기적으로 진행하고 하는 데이터베이스가 필요하다.
그 역할을 프로메테우스가 능동적으로 수행한다.
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-configmap
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['192.168.0.3:9100']
- job_name: 'nvidia'
static_configs:
- targets: ['192.168.0.3:9400']
- job_name: 'docker'
static_configs:
- targets: ['192.168.0.3:9323']
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.0.3:8080']
~프로메테우스의 설정사항들이다.
앞으로 nvidia 정보, 도커 컨테이너 정보, 클러스터 정보 등등을 얻을 것이기 때문에 미리 적어줬다.
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
spec:
type: NodePort
ports:
- protocol: TCP
port: 9090
targetPort: 9090
nodePort: 30090프로메테우스 서비스 정의다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi프로메테우스 컨테이너가 내려가더라도 계속 정보가 남아있도록 볼륨을 붙여준다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-server
template:
metadata:
labels:
app: prometheus-server
spec:
containers:
- name: prometheus
image: prom/prometheus:latest
ports:
- containerPort: 9090
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
volumeMounts:
- name: prometheus-data
mountPath: /prometheus
- name: prometheus-configmap
mountPath: /etc/prometheus
volumes:
- name: prometheus-data
persistentVolumeClaim:
claimName: prometheus-pvc
- name: prometheus-configmap
configMap:
name: prometheus-configmap프로메테우스 배포
이렇게 배포한 프로메테우스로 들어가 볼 수있다.
그런데 계속 pending 상태인 것을 볼 수 있을 것이다.
describe 를 보면 pvc에 문제가 있다고 하는데 pv 가 준비되지 않아서 그런 것이다.
pv는 클러스터가 실재로 가용할 수 있는 스토리지로
통신을 통해 데이터를 저장, 불러올 수 있는 스토리지 백엔드가 필요하다.
그래서 여러대의 노드를 쓸 때도 한대의 스토리지처럼 사용할 수 있도록 하는 것이다.
pvc는 pv에 사용 요청을 보내는 것으로 pv가 없으면 무용지물이다.
kubeadm은 pv를 자동으로 생성하지 않으므로 pv 를 생성해줘야 하는데
싱글노드에서 가장 간단한 방법인 호스트 스토리지를 바로 쓰는 방법을 써보자.
그렇지 않은 경우에는 스토리지 백엔드가 반드시 필요하다.
apiVersion: v1
kind: PersistentVolume
metadata:
name: kube-data
spec:
capacity:
storage: 3Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /kube-data이렇게 최상위 폴더 위에 스토리지를 연결했다.
없다면 반드시 만들어줘야 한다.
pv는 클러스터 스코프 리소스로 별도의 네임스페이스가 필요하지 않다는 특징을 가지고 있다.
pvc로 나눠 쓸 때만 네임스페이스가 필요하다.
아래와 같이 pvc를 수정했다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: my-hostpath-pv
이렇게 했더니 쓰기 권한의 문제 때문에 파드가 계속 실패하는 상황이 발생했다.
아래 구문을 deployment에 추가하여 권한을 변경하고 다시 apply 해주었다.
# sudo chown -R 1000:1000 /kube-data 실행 후
spec:
containers:
- name: prometheus
...
securityContext:
runAsUser: 1000 # UID
runAsGroup: 1000 # GID
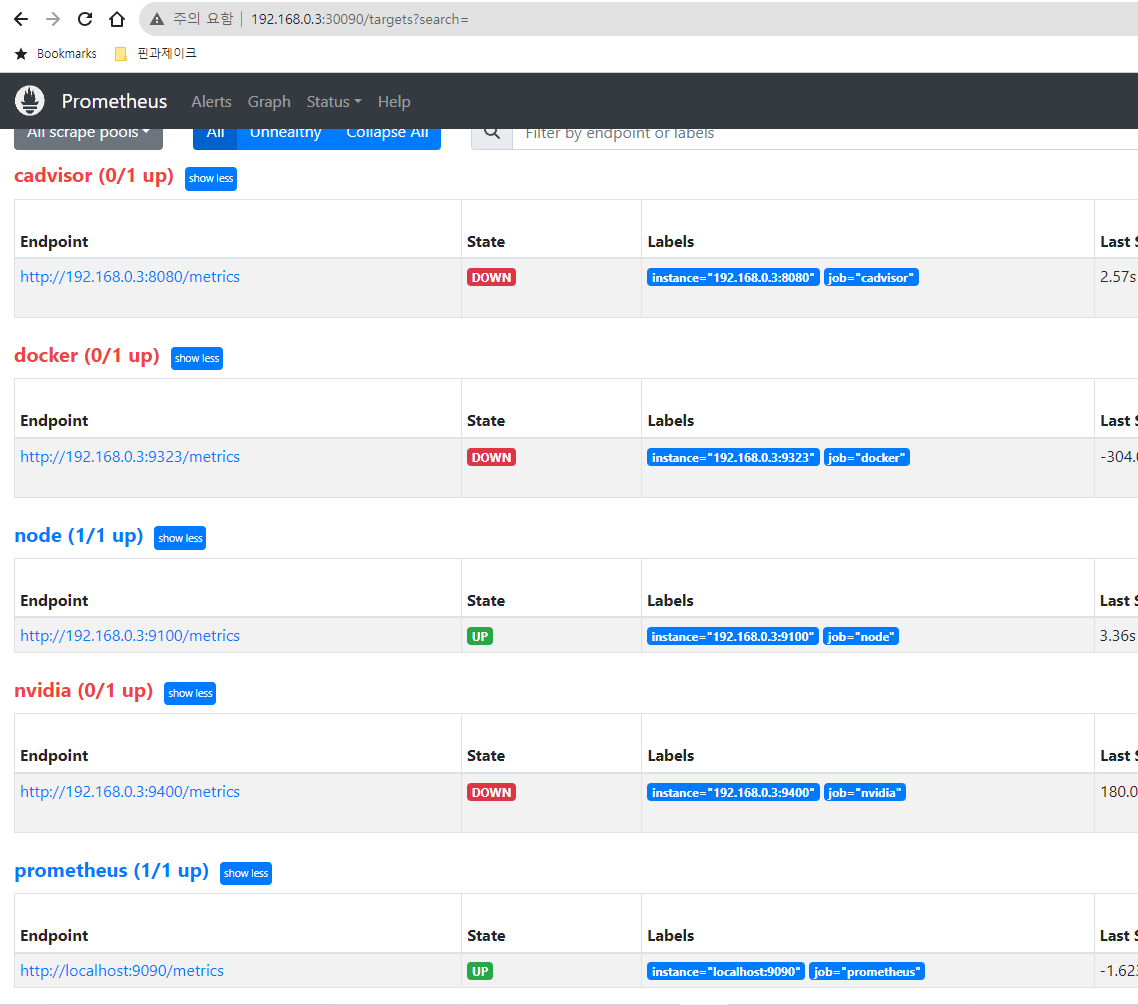
아직 뜨지 않은 타겟은 읽어오지 못하고 노드 익스포터는 잘 읽어온다.
다음 글에서 그라파나까지 가보자.
'Backend MLOps > On-premise setting' 카테고리의 다른 글
| [k8s] 라즈베리파이 클러스터링 -1 (2) | 2023.08.27 |
|---|---|
| [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 4 (0) | 2023.08.24 |
| [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 2 (2) | 2023.08.23 |
| [k8s] kubeadm 을 이용해서 싱글노드 쿠버네티스 환경 구축 - 1 (0) | 2023.08.17 |
| [k8s] 쿠버네티스 찍먹 - 2 (0) | 2023.03.02 |




댓글