이번에는 Postgresql을 작동시키고
sqlalchemy를 이용해서 파이썬에 연동하고
그걸 fastapi로 확인하는 방식의 동작들을 수행해보자.
이단계에서 필요하다면 컨테이너를 빌드하고 소통하는 방식으로 진행해 볼 것이다.
우선 postgresql은 설치가 되어있는 상태다.
main.py 가 있는 디렉토리와 같은 위치에 db 폴더를 따로 만들고 거기를 db로 지정해보도록 하겠다.
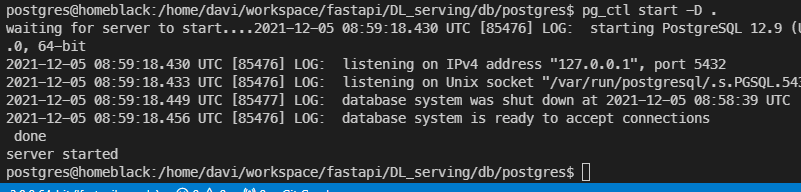
db 의 권한을 777로 바꿔주고 그 아래에 postgres 라는 디렉토리를 생성 pg_ctl로 db를 시작해 주었다.
정상적으로 postgres 서버가 동작하는 모습
이때는 postgres의 관리 권한이 있는 계정으로 넘어가서 작업을 해 주어야한다.
postgres 설치시에 자동으로 postgres라는 관리 계정이 생성되는데
su - postgres 를 통해서 계정을 바꾼 후 작업을 진행할 수 있다.
이제는 db와 연동하는 부분의 .env를 작성해주어야한다

cat 을 이용해서 간단한 문서를 작성한다.
<< 명령어는 끝나는 지점을 명시하고
> 명령어는 내용을 redirection 할 파일 이름을 받는다.
> 인 경우 작성된 내용을 지우고 파일을 덮어쓰지만
>> 인 경우 아래에 덧 붙여 작성된다.
<< EOS 로 시작했으므로 EOS를 입력하면 파일 작성이 끝난다.
EOS 는 End Of Sequence 의 약자로 End Of File 의 EOF 를 쓰기도 한다.
아무튼 이렇게 하면 이전 포스트에서 작성한 database.py 파일의 필요한 부분이 다 채워졌다.
.env에 작성한 사용자가 아직 postgrespl에 등록되어 있지 않으므로
실행하면 오류가 날 것으로 예상할 수 있다.
지금은 등록하지 않고 코드에 조금 더 집중해서 나중에 에러가 발생하면 해결하도록 하자.
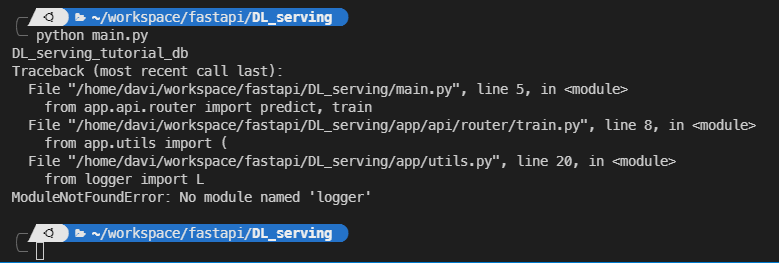
main.py를 실행했을때 화면이다. logger를 아직 작성하지 않아서 찾을 수 없다는 문구가 떴다.
혼자서 개발할때는 print 문 정도만으로도 충분히 중단점을 잡아내거나 코드의 inspection 을 캐치할 수 있지만
팀을 이뤄서 코드를 완성해야할때는 log 를 잘 활용하는 것이 굉장히 중요하다.
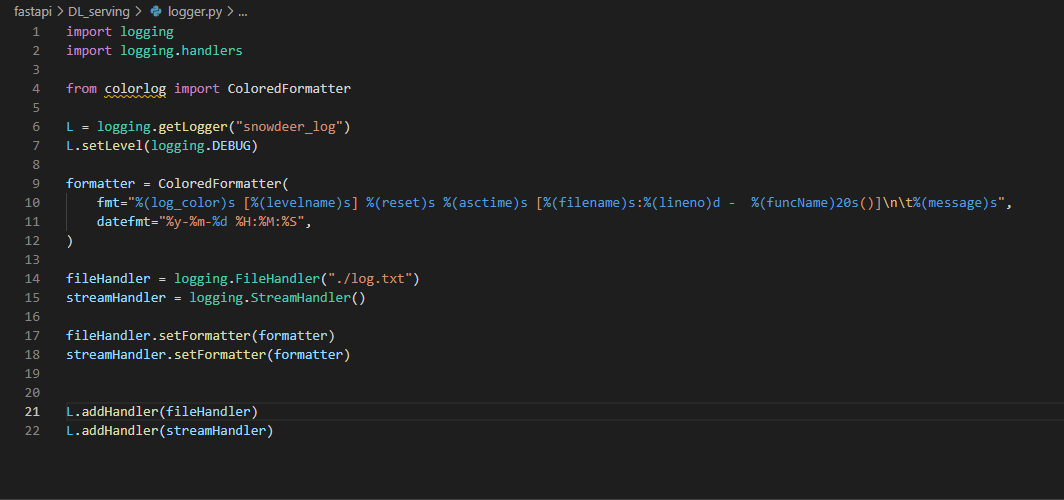
로그에 대한 부분은 이번 글의 논외이므로 넘어가고 작성된 로거를 사용하는 것만 이해하자.

main.py 를 실행한 결과인데 아직 prediction은 추가하지 않은 기능이므로 main.py 에서 사용하는 부분은 지원준다.
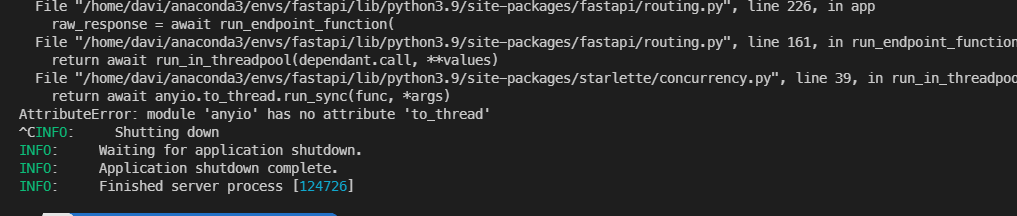
main을 실행해주면 저렇게 에러메세지가 뜨는데
아직 버전이 낮다보니 이런 자잘한 이슈들이 많이 나오는 것 같다.
anyio 의 docs를 살펴보니 to_thread 라는 모듈이 3.0.1 버전부터 지원을 하도록 되어있다.
그래서 anyio의 버전을 올려주니 해결됐다.

이번에는 postgresql의 파일시스템을 변경할 수 없는 권한이슈가 발생했다.
postgres 계정으로 넘어가서 db/postgres 의 권한을 변경해준다

자세한 권한 설정을 통해서 보안성을 높여주는 작업이 필요하겠지만
지금은 quick start 인 만큼 첫 동작이 이루어지는데 집중한다.
chmod 는 -R 옵션을 통해서 recurrently 하위 디렉토리들을 변경할 수 있다.
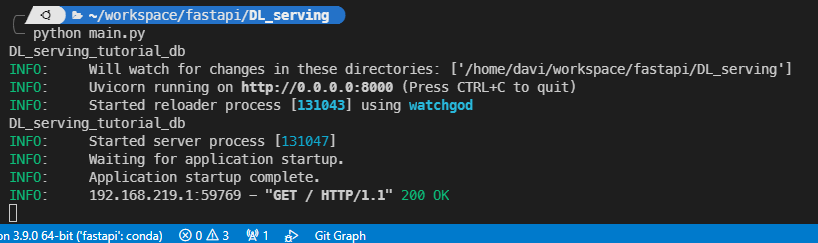
서버가 정상적으로 열렸고 같은 사설망 내의 컴퓨터로 접속이 로그된 모습이다.
train.py 에서 router를 만들때 prefix를 /train으로 설정하고 /insurance 를 path로 지정했으므로 그 위치로 가보도록 하자

이런 에러가 발생하는데 나는 웹 브라우저를 통해서 GET method를 사용했으니 이런 에러가 발생한 것이다.
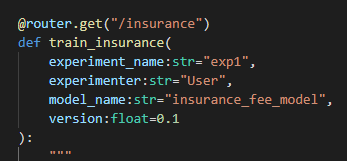
router의 method를 put에서 get으로 바꿔주고 돌리면 아래의 함수가 실행된다.
우리는 nni를 설치하고 동작시킨 적이 없으므로 nni를 실행할 수 없다는 에러가 발생하면 잘 동작한 것이다.
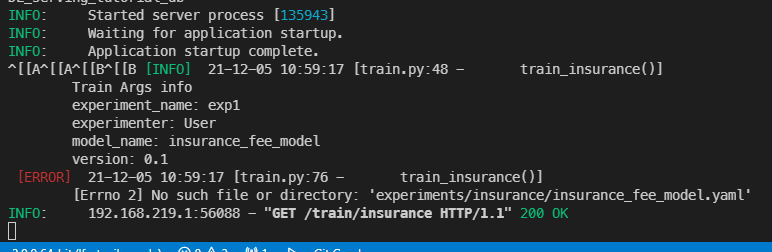
보면 에러가 발생하긴 했는데 nni에 대한 에러가 아니라 yaml 파일을 만드는데 에러가 났다.
experiments 디렉토리를 만들지 않아서 발생한 문제인데
os.makedirs 를 이용해서 디렉토리가 없을 경우 생성해주는 분을 추가하자.

추가하는 김에 nni 에러를 더 확실하게 볼 수 있는 부분을 else 로 추가해줬다.

우리가 원했던 nnictl 이 없다는 에러가 발생했다.
그러면 이제 nnictl을 설치해서 동작하는지 확인하자.
https://github.com/microsoft/nni
GitHub - microsoft/nni: An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, ne
An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning. - GitHub - microsoft/...
github.com
공식 github을 가보면 설치부터 trial 까지 모두 안내되어있다.
trial을 하나 실행해 보면
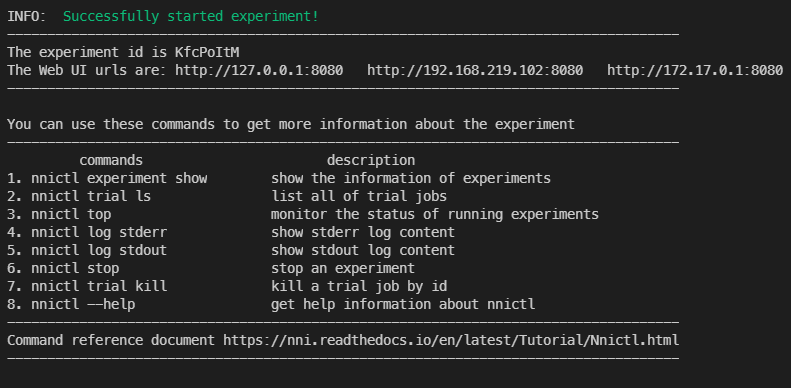
이렇게 nni 서버가 잘 실행된 것을 볼 수 있다.
조금 미스터리한 부분인데 127.0.0.1로 접속을 해도 다른 컴퓨터에서 대시보드로 접속이 가능하다...
아무튼 이제 nni의 동작이 확인되었으니 열린 서버를 닫고 우리 프로젝트의 main.py 를 실행해보자.

확대해서 보면 search space 에 대한 정의가 없다고 나온다.
이건 기본적인 NNI 의 사용법을 숙지하지 않았기 때문인데
https://nni.readthedocs.io/en/latest/TrainingService/LocalMode.html
Tutorial: Create and Run an Experiment on local with NNI API — An open source AutoML toolkit for neural architecture search, m
You can download nni source code and a set of examples can be found in nni/examples, run ls nni/examples/trials to see all the trial examples.
nni.readthedocs.io
이 부분과 안내되는 tutorial, 그리고 write_yaml 함수를 이용해서 제작하는 yaml 까지 들여다 보면
nni 기본 설정을 마칠 수 있다.
나중에는 이 부분을 optuna 라던지 wandb sweep 이라던지 MLFlow, KubeFlow 등으로 바꾸면서
계속 업그레이드 해 나가면 될 것이다.
지금은 nni를 동작시켜 보자.

작성된 yaml을 보면 trial.py 파일과 search_space.json 파일을 미리 작성해 주어야하는 것을 알 수 있다.
따로 경로지정이 없으니 insurance_fee_model.yaml 파일이 있는 위치로 이동해서 작성하면 된다.
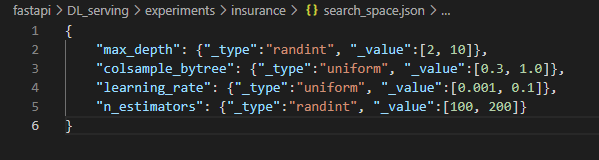
간단한 search_space를 json 파일로 입력해 준다.
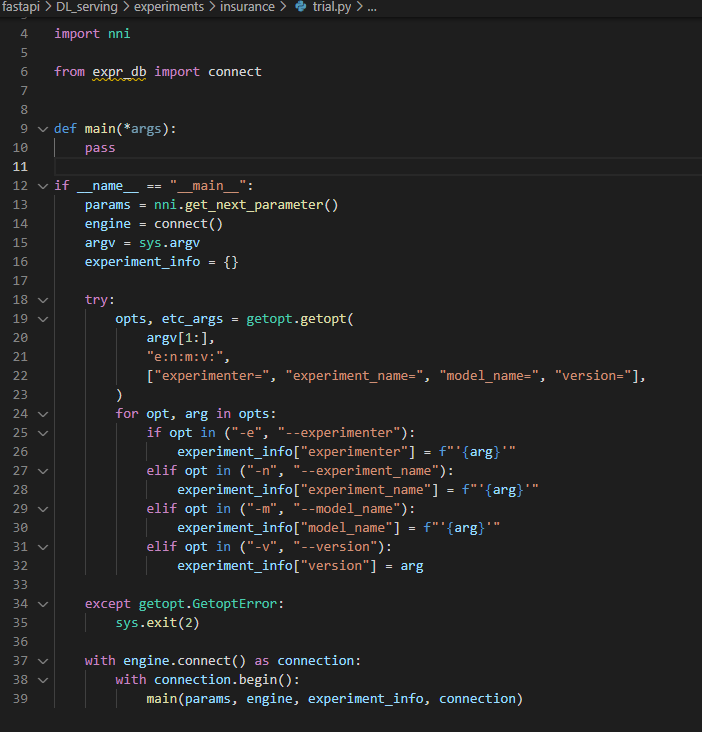
그리고 trial.py 파일을 작성하는데
getopt 는 option을 잘 파싱하기 위한 부분이고 argsparser 와 같은 역할을 한다고 보면 된다.
그 부분이 해결되고 나면 nni로 부터 다음 실험 변수를 받아오는 부분
그리고 db와 연동된 engine을 만드는 부분을 볼 수 있다.

깃헙 원본에서는 두가지 이상의 모델이 공통으로 사용하는 db 연결 구문이 있어
디렉토리가 하나 위에 작성되어 있다.
sys.path.append 를 이용해서 expr_db.py 가 있는 경로를 path에 등록한다.
그리고 아까 작성한 .env 와 동일한 .env 파일이 있으면 될 것이다.
복사해서 가지고 와 준다.
이제 trial.py 의 main을 만들어 볼 차례인데

db와 연동하기 위해서 query를 미리 작성해 둔 부분이 있다. 역시 붙여 넣어서 가져오고
pandas를 이용해서 rdb를 바로 DataFrame으로 가져오는 것을 볼 수 있다.
나머지 부분도 모두 붙여와 준다.
모델을 연구하는 것 보다 큰 틀을 어떻게 짜는지 알아보는 중이기 때문에 모델을 빌드하는 부분은 넘어가도록 한다.
개략적으로 보자면
XGBRegressor 를 만들어서 학습하고
모델의 성능을 측정하고
학습된 모델을 pickle로 dump 하고 이 객체를 mime base64 로 이진화 하도록 encoding 한다.
그리고 모델의 성능과 encode된 모델르 쿼리로 날려서 db에 저장한다.
이제 모든 준비가 마쳐졌으니 한번 돌려볼텐데
돌리면 .env 에 적어둔 db 정보가 아직 postgres에 없어서 에러가 날 것이다.
한번에 잘 돌아가는 것도 중요하지만
이때까지 작성된 코드가 어디까지 진행되었고
따라서 어떤 에러가 발생할 것이고 어떻게 처리하면 되는지
중단점을 잘 찾아서 코딩하는 것도 좋은 방법이라고 생각한다.

역시 postgres에서 FASTAPI_USER라는 role을 만들지 않아서 문제가 발생했다.
db를 수정해서 FASTAPI_USER 라는 role을 만들어 보자.

관리자 계정으로 접속해서 postgres db서버에 접속해 준다.
그리고 db 목록을 보면 아직 아무것도 없다.
.env에 DB이름을 DL_serving_tutorial_db 라고 했으므로 이 이름이 있는 db를 만들어 준다.
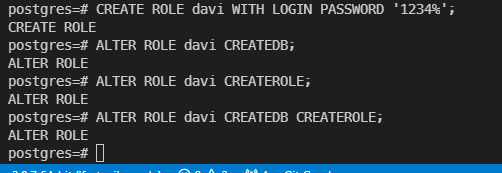
주로 작업하는 계정에서 DB를 새로 만들고 계정도 새로 만들 수 있도록 권한을 줬다.
어떻게 할까 고민하다가 저렇게 여러번 친건데 그냥 맨 밑에꺼 한줄만 하면 된다.
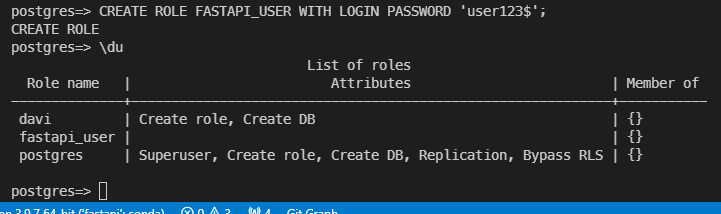
이렇게 davi로 넘어와서 fastapi_user 까지 만들어 줬다.
그리고 main을 돌려보면 .env에서 대문자로 적은 부분들이 모두 에러가 발생한다.
모두 소문자로 고쳐주자.
그리고 돌려보면

DB의 테이블이 없다고 나온다.
테이블이 어떻게 설계되었는지는 app/models.py 를 참고하면 알 수 있다.
[postgreSQL] 데이터베이스 생성, 테이블 생성 & 데이터 입력
이번 글에서는 psql이나 pgAdmin을 사용하여 데이터베이스 생성, 테이블 생성과 데이터 입력하는 법을 정리해보겠습니다. SQL 쉘(psql)에서 데이터베이스 생성 CREATE DATABASE 이름; SQL 쉘에서 students 데
benn.tistory.com
https://velog.io/@moorekwon/PostgreSQL-%EB%8D%B0%EC%9D%B4%ED%84%B0-%ED%83%80%EC%9E%85
PostgreSQL 데이터 타입
PostgreSQL 데이터 타입n은 양의 정수p는 초 필드에 보유되는 소수 자릿수를 지정하는 정밀도 값, 범위는 0에서 6까지비트 문자열: 1과 0의 문자열Pseudo: 함수의 동작이 단순히 특정 SQL 데이터 유형의
velog.io
위의 두 블로그를 참고해서 테이블을 만들어 준다.
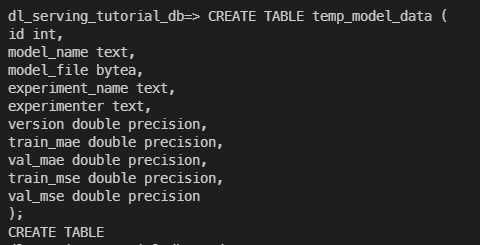
노가다로 만들어줬다.
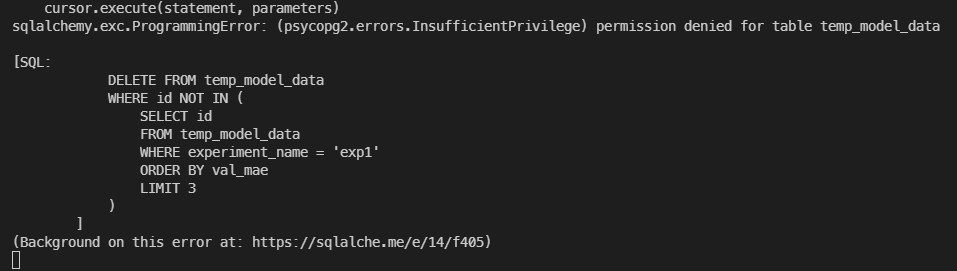
테이블의 수정 권한이 없다.


DB 수정 권한과 테이블 수정 권한을 준다.
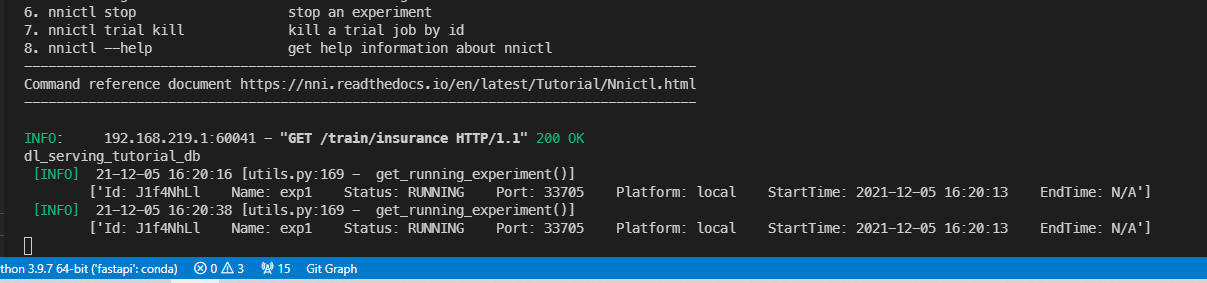
동작하는 것을 알 수 있다.
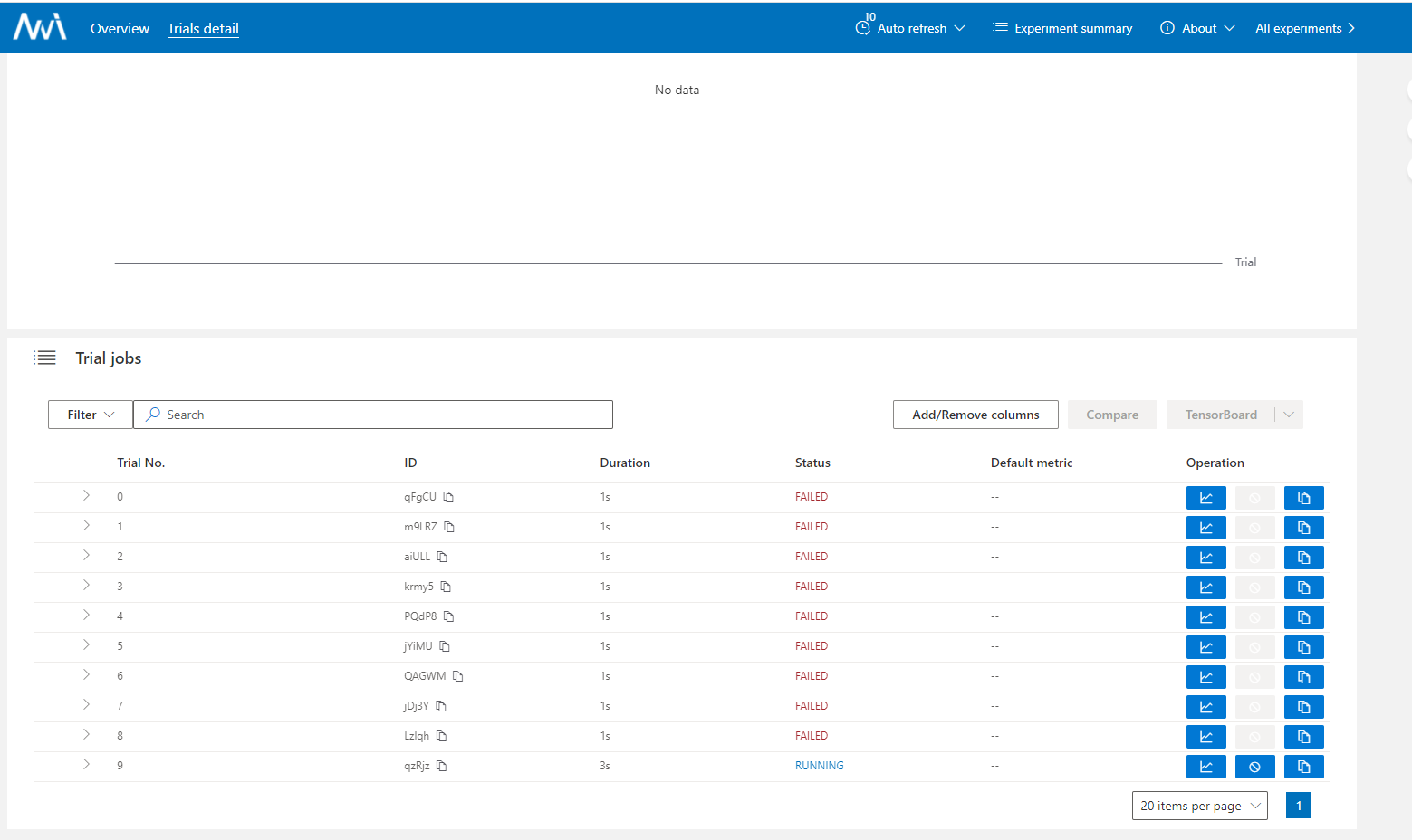
NNI 데시보드를 보면 동작은 하는데 학습에 실패하는 것으로 보아 어딘가 문제가 생긴 모양이다.

로그를 보니 미리 데이터들을 DB에 쌓아두고 실험을 진행했다고 보여진다.
이 부분을 수정하면 실험 진행이 원활하게 될 것이다.
https://www.kaggle.com/mirichoi0218/insurance/version/1
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
캐글에서 동일한 column을 가지는 데이터를 찾았다.
csv 파일을 바로 postgres 로 업로드 할 수 있는 방법이 있어서 시도해 보기로 했다.
COPY 문을 이용해서 csv 파일을 DB에 올린뒤 GRANT로 권한을 모두 주고
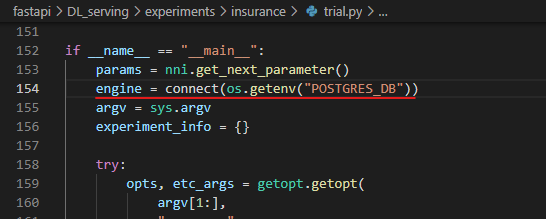
trial.py에서 DB 엔진을 만드는 부분이 맞지 않아 이렇게 고쳐주었다.
학습이 잘 이루어지는 모습을 볼 수 있다.
이제 원래 기능이었던 train부분을 put 으로 바꿔주고 swagger 에서 컨트롤 할 수 있는지 보자.
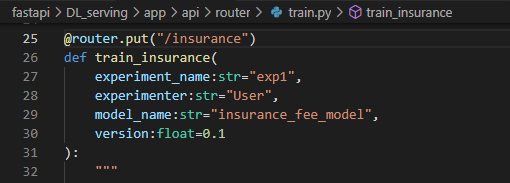
요렇게 put으로 바꿔주기만 하면

swagger를 통해서 컨트롤 할 수 있게 된다.
지금까지 한 것을 정리하면
웹서버를 열고
DB 서버를 열고
NNI 서버를 열고
웹 - DB 간의 소통을 정의하고
웹 - NNI - DB 로 이어지는 데이터 파이프라인을 연결한 상황이다.
사실 웹 - NNI서버 의 연결은 REST API로 구현하지 못했으므로
containerize했을때 완벽히 분리 시킬 수 없는 상태다.
또 학습 기록 정도만 할 수 있으므로 완벽한 서빙을 구현한 것도 아니다.
다음 글에서는 모델을 로드해서 서빙하는 부분이나
혹은 MLFlow 를 이용하여 모델을 학습하고 모델 레지스트리에 올리는 것으로
웹 서버와 DL 서버를 분리해보는 시도를 해보자.
'Backend MLOps > Fastapi' 카테고리의 다른 글
| [Fastapi] asyncio 제대로 써보기 with pytest - 2 (0) | 2022.06.14 |
|---|---|
| [Fastapi] asyncio 제대로 써보기 with pytest - 1 (0) | 2022.06.03 |
| [DL Serving] FastAPI 튜토리얼 - 3 (0) | 2021.12.05 |
| [DL Serving] FastAPI 튜토리얼 - 2 (0) | 2021.12.04 |
| [DL Serving] FastAPI 튜토리얼 (0) | 2021.12.01 |



댓글