R-CNN
- 객체가 있을만한 후보위치(Region of Interest)를 기존의 알고리즘으로 예측
- 예측된 후보 위치를 crop 후 warpping
- warpping 된 이미지를 분류
- sliding window 는 너무 많은 경우의 수 -> Selective search 를 이용해서 후보 추출
- 아래의 step으로 진행
1) 입력 이미지 받기
2) Selective search 적용 : 하나의 이미지에서 2000개의 RoI 추출
3) 동일한 size로 warpping : 분류기의 마지막에 fc레이어에서는 고정된 사이즈를 받아야함
4) warpping된 RoI를 CNN 에 넣어 feature 를 추출
5) 추출된 feature를 SVM에 넣어서 분류 진행
6) regression을 진행해서 bbox를 보정하는 값을 예측
- AlexNet fine tuning
- 적용하고자 하는 Domain에 대해서 finetuning
- RoI와 Ground truth 의 IoU 계산
- 0.5 이상이면 positive sample 미만이면 negative sample
- positive 32, negative 96 = 128개의 이미지 1 batch
SPPNet
- crop and warpping 하는 과정에서 발생하는 정보 왜곡을 최소화 함
- Spatial Pyramid Pooling 을 도입
- target size 를 먼저 정한 후에 그 size 만큼 등분하여 만들어진 영역을 pooling
- 여러가지 Bin size를 통해서 pooling 을 각각 시도하고 그에 따라 feature vector를 생성
Fast R-CNN
Pipeline
1) 이미지를 VGG16에 넣고 feature map 추출
2) 원본 이미지의 selective search RoI를 feature map에 projection 해 줌
- feature map이 원본의 1/10 이라면 RoI를 같은 비율로 줄여서 맵핑
3) feature map 상에서 얻어진 RoI 를 고정된 크기의 feature vector 로 변환해줌
- SPP 를 이용하지만 target size를 7x7 하나만 사용하게 됨
4) softmax classifier 와 bounding box regressor를 통과하여 결과를 얻음
- class의 수 + 배경(unknown)
- multi task loss : softmax classifier 와 bounding box regressor
- Classification : Cross entropy
- BB regressor : Sommoth L1 (outlier에 덜 민감하게 반응함)

- Dataset
- 0.5 < IoU : positive samples
- 0.1 < IoU < 0.5 : negative samples
- 이렇게 나눈 데이터들을 p-sample 25% n-sample 75% 로 구성
- Hierachical sampling (이해가 잘 안된다 -> 논문 볼 것)
- 한 batch에 한 이미지의 RoI만을 포함함
- 한 배치 안에서 연산과 메모리를 공유할 수 있음
-> 거의 End-to-End로 동작하지만 아직 완벽한 E2E 라고 볼 수는 없음
Faster R-CNN

- Selective search 를 제거하고 RPN 이 selective search를 대체할 수 있도록 했음
Pipeline
1) CNN으로 feature maps 추출
2) RPN을 통한 RoI 계산
- Selective search 대체 -> Anchor box 사용
- SPP 는 임의의 위치에 있는 객체와 임의의 크기를 가지는 객체를 맞추기 힘들다
- 중앙을 맞춘 후 여러가지 미리 정의된 박스를 사용하는 방식이 anchor box
- RPN은 anchor box들이 객체를 얼마나 가지고 있는지 근거를 주고 box를 미세 조정하도록 하는 네트워크

- 각 픽셀별로 9개의 anchor box가 객체를 포함하는가?
- 각 픽셀별로 9개의 anchor box를 어떻게 조정해야하는가?

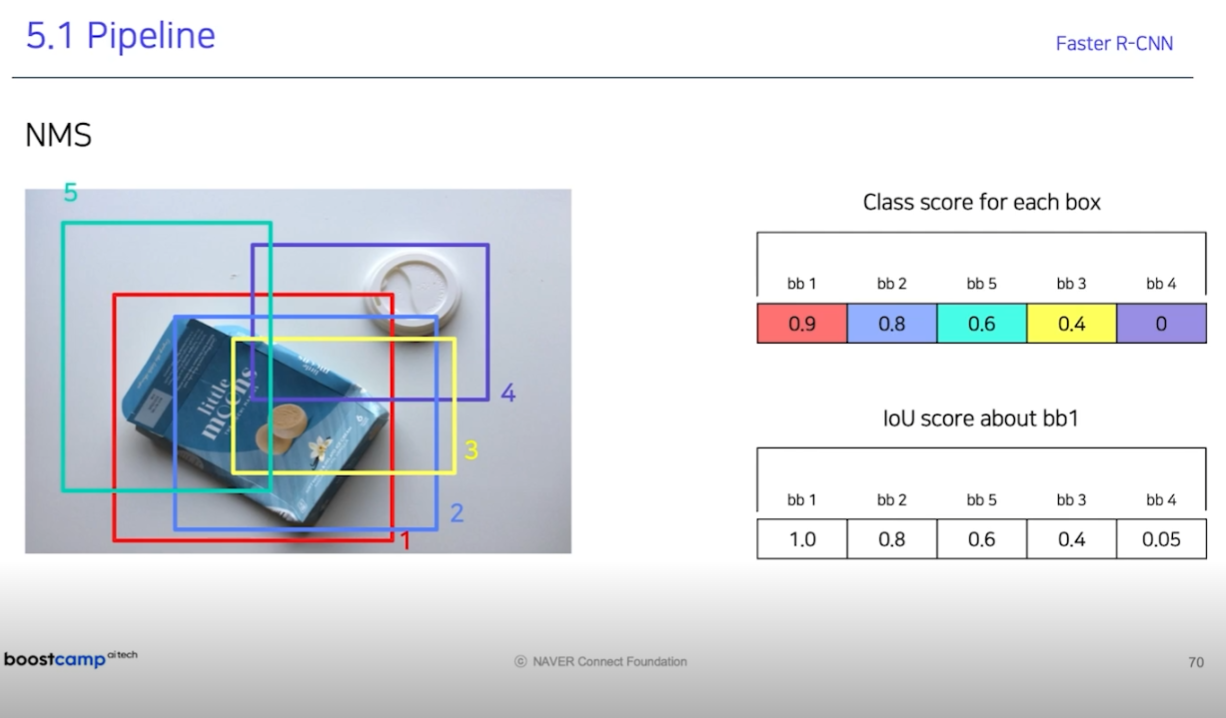
3) NMS
- 중복된 box를 제거하는 과정
- 각각의 추론된 box에 대한 IoU를 측정
-> IoU가 가장 높은 box A를 선정
-> A에 대하여 나머지 박스에 대한 IoU추론
-> A와 너무 많이 겹치는 박스는 class를 0으로 바꿈
RPN training
- RPN 단계에서
- IoU > 0.7 or 어떤 ground truth와 가장 높은 IoU를 가지는 박스 : positive samples
- IoU < 0.3 : negative samples
- 0.3 <= IoU <= 0.7 : 학습에 사용하지 않음

Faster R-CNN training

'딥러닝 머신러닝 데이터 분석 > BoostCampAITech' 카테고리의 다른 글
| [LV.3 모델 최적화] #5 Augmentation (0) | 2021.11.24 |
|---|---|
| [LV3 모델최적화] #2, #3 (0) | 2021.11.24 |
| [Lv2 P-Stage] Object Detection Overview (0) | 2021.09.27 |
| [CV] Further topics of segmentation (0) | 2021.09.19 |
| [CV] Object detection (0) | 2021.09.12 |


댓글