GAN 훈련
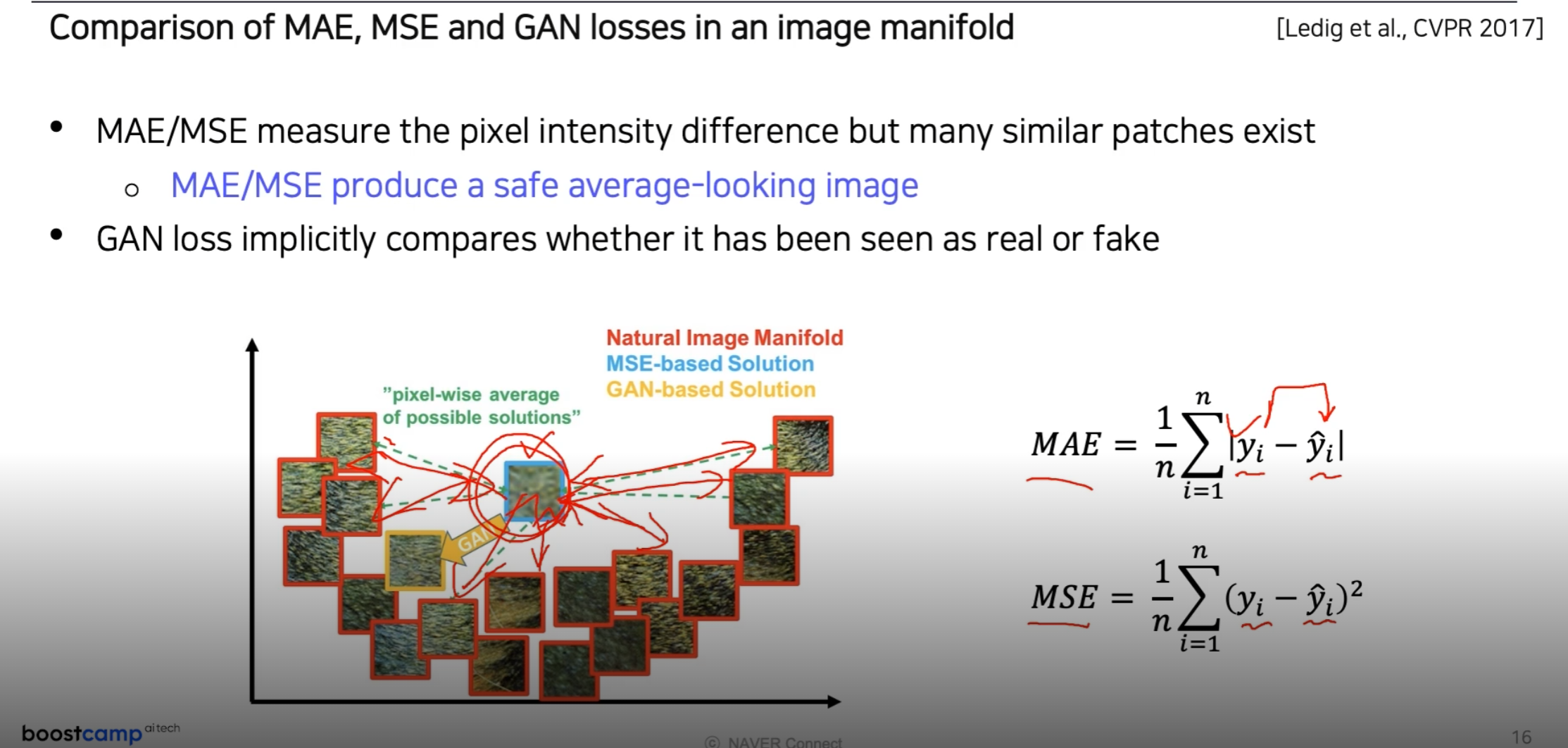
- MAE/MSE 의 경우 manifold를 학습하기 보다는 sample space에서 평균적인 점을 찾음
- 따라서 blurry한 영상을 얻게 됨
- GAN의 경우 sample space의 manifold를 찾기 때문에 더욱 선명하고 실재와 같은 data를 생성 가능
Pix2Pix [Isola et al., 2017]
- semantic segment -> image 로 만드는 작업
- gray scale -> colorization
- paired data가 필요
CycleGAN[Zhu et al., ICCV 2017]
- paired data가 필요하지 않음
- Consistancy를 이용한 학습
- bidirection GAN loss + Cycle-consistancey loss를 이용한 학습
- unsupervision, self-supervision 방식을 사용
Perceptual loss [Johnson et al., ECCV 2016]
- pretrained network가 필요함
- 학습이 쉽고 간단함
- 일반적인 네트워크의 학습과 동일
- 간단한 학습을 통해서 style transfer 가능
- content target : 시진에 있는 컨텐츠가 바뀌는지 보기 위한 타겟
- 원래 사진을 사용하는 경우가 많음
- feature 간의 l2 loss
- style target : 바꾸고자 하는 스타일을 가지고 있는 타겟
- feature의 gram matrices를 구하고 그 행렬 사이의 loss 를 사용함
further topic
- deepfake
- deepfake detection
- face de-identification [Ganfni et al., ICCV 2019]
- face anonymization [Gu et al., ECCV 2020]
- Video translation and manipulation
댓글