대회 목적
사람의 얼굴이 찍힌 사진을 인식하여 나이 / 성별 / 마스크 착용상태를 동시에 예측하는 모델 만들기
EDA
주의 : 대회에 사용된 모든 사진은 캠프 교육에만 활용될 수 있음. 외부 유출 금지.
메타 데이터
CSV 형태의 메타데이터가 주어지고 ID, 성별, 나이, 인종 이 주어짐.
이 셋을 "_"로 조합하면 해당 인물에 대한 사진이 들어있는 폴더 경로가 주어짐.
각 인물당 마스크를 바르게 착용한 사진 3장, 착용하지 않은 사진 1장, 바르지 않게 착용한 사진 1장
총 7장의 사진이 주어짐.
예측해야하는 라벨은
성별 : 남/녀
마스크 : 착용 / 미착용 / 오착용
나이 : 30세 미만 / 30세 이상 / 60세 미만 / 60세 이상
의 총 18가지 라벨을 예측.
성별

남녀간의 성비를 조사한 결과 1.5 : 1 정도의 비율을 보이는데 학습에 큰 지장을 주지는 않을 것이라 판단함.
필요시 1:1 로 맞추는 subsample 작업 필요.
사진을 하나하나 눈으로 확인하다보면 머리가 짧은 여성이나 머리가 긴 남성 등 중성적 외모의 사진도 다수 존재함.
라벨링이 잘못된 경우도 있음.
나이
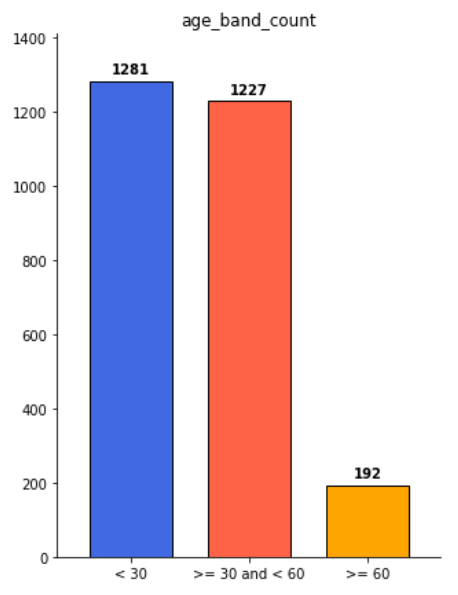
라벨대로 나누어본 결과 60세 이상이 두드러지게 적은 것을 알 수 있음.

나이의 경우 분석결과 60세가 최고령으로 나타남.
단순 분류문제로 접근할 경우 60세 이상을 분류하는데 상당히 어려울 것으로 예상됨.

나이대를 더 상세하게 나눠도 불균형이 상당히 심각하다는 것을 알 수 있음.
또 50대 이상만 돼도 피부색이나 얼굴 주름이 60세와 비슷한 수준으로 나타남.
CNN등의 텍스쳐 기반 모델은 분류가 어려울 수 있겠다고 판단됨.
특히 크리티컬하게 구분해야하는 50~60 세와 60~ 세 구간에서 불균형이 압도적으로 나타남.
마스크
마스크의 경우 착용 : 미착용 : 오착용 의 비가 5 : 1 : 1로 고정
불균형 극복 필요.
모든 인물에 대해서 7장의 사진이 있음. 누락 없음.
사진의 확장자는 jpeg, jpg, png 3가지.
조사결과 jpeg 와 jpg는 완전히 동일하고
단지 윈도우의 낮은 버전에서 3글자 확장자를 사용해야해서 도입된 것이라고 함.
png의 경우 이미지를 읽어오는 PIL 패키지에서 정식으로 지원하는 확장자.
따라서 확장자를 전처리해줄 필요는 없음.
모든 이미지의 크기는 384 x 512 x 3 으로 동일함.
착용의 경우 마스크의 종류가 매우 다양함, 예를 들어 흰색, 하늘색, 꽃무늬, 캐릭터 등등
착용의 스카프나 손수건을 두른 경우도 있음.
오착용의 경우 턱에만 써서 콧구멍이 보이는 경우가 대부분임.
하지만 눈이나 코만 가리는 식으로 착용한 경우도 있음.
미착용의 경우 머리부터 목까지 완벽하게 노출되는 사진들임.
배경이 넓고 사진의 중앙에 얼굴이 나타나도록 찍은 것이 특징.
다양한 배경 때문에 학습이 어려울 수 있음.
모든 사진의 값을 합하고 사진의 장수만큼 나누어준 결과.
평균 이미지로 볼때 얼굴이 등장하는 구간은
( 80, 50 )
( 80 + 220, 50 )
( 80, 50 + 320 )
( 80 + 220, 50 + 320 )
의 박스 안으로 추정됨.
테스트 데이터에 대해서도 동일한지는 검증필요.
박스로 crop한 결과와 그렇지 못한 결과를 비교하여 성능이 향상된다면 더 좋은 crop 기법을 찾아서 적용해야 할 것.
실험 1 - Generative Model
데이터의 불균형이 매우 심한 경우이고 라벨링 또한 오류가 있는 경우 이므로
일반적인 분류 모델을 위한 supervised learning으로는 generalized model을 얻기 힘들 것이라고 가정.
supervised learning이 아닌 방법을 이용하는 아래의 두 가지 전략을 구상함.
실험 1. 1 : 데이터의 불균형이 심하므로 generative 모델을 이용하여 이미지의 매끄러운 latent space를 찾은 뒤
거기에서 mapping된 값이 군집을 형성하는지 확인하고 각 군집을 구분하는 문턱값을 줘서 분류.
실험 1. 2 : 각각의 라벨로 condition을 줘서 학습데이터를 generate하도록 학습한 뒤
test이미지를 모든 라벨에 대해서 reconstruction하여 reconstruction loss가 가장 작은 라벨을 선정.
실험 1. 1
가설 : 성별의 불균형이 가장 낮은 것을 확인했으므로 latent space에서 형성되는 군집을 확인하는데 좋을 것이다.
검증 : 간단한 AAE 를 통하여 성별을 분류하되 마스크를 쓰지 않은 맨 얼굴(2700장)을 복원하도록 하여 latent vector의 tsne 등을 확인해본다. AAE는 convolution을 적용하여 spatial dimension을 줄이고 channel을 늘리는 방향으로 학습하고
병목 직전에 latent vector를 얻기 위하여 linear mapping 을 1번 거친다. 그리고 얻어진 latent vector는 다시 linear mapping을 통해 spatial dimension을 회복하고 convolution transpose를 이용해서 원본 이미지 크기까지 회복한다.
결과 :
저작권 상 사진 노출은 불가능.
전체적인 형태까지 파악하고 디테일은 잘 살리지 못함.
얼굴형, 피부색, 머리색, 머리스타일 등은 잘 복원하지만 얼굴의 이목구비가 뭉뚱그려져서 복원됨.
개중에는 아주 형편없는 복원도 있음.
반성 :
1. 모델을 키울 것. 빠른 검증을 위해서 모델을 너무 작게 만든 것이 이유일 수 있음.
사람 얼굴에 적용한 backbone모델을 찾아서 비슷한 크기의 모델을 적용해 볼 것.
2. 데이터를 늘려볼 것. 역시 빠른 검증을 위해서 2700장의 사진만을 사용한 것이 문제일 수 있음.
마스크를 쓴 사람들의 얼굴은 5배에 달하는 양으로 데이터가 풍부하므로 마스크 쓴 사람의 데이터도 넣어서 훈련해 볼 것.
3. condition을 줘서 훈련해 볼 것. 중성적인 데이터의 비율이 얼마나 되는지 정확히 알 수 없으므로 prior distribution을 구분해서 학습하거나 condition을 주는 것으로 latent space를 더 확실하게 구분하도록 학습해 볼 것. 다만 이 경우 라벨의 오류는 감안해야함.
실험 1. 2
가설 : 나이와 성별등을 conditioning 할 수 있는 CAAE에서 각 이미지의 라벨 별로 복원되게 학습하면 원본 이미지의 라벨이 아닌 다른 라벨로 복원했을때 원본과의 차이가 커질 것이다. 따라서 condition별로 reconstruction loss 가 가장 작은 이미지를 고르면 그 이미지의 label이 될 것이다.
검증 : 얼굴을 학습하고 성별과 나이를 conditioning 할 수 있는 backbone 모델을 이용하여 마스크 라벨을 추가적으로 학습하면 성별, 나이, 마스크 착용 여부에 대해서 reconstruction이 가능할 것이다.
참고한 모델들 )
https://github.com/Jooong/Face-Aging-CAAE-Pytorch
GitHub - Jooong/Face-Aging-CAAE-Pytorch: Age Progression/Regression by Conditional Adversarial Autoencoder
Age Progression/Regression by Conditional Adversarial Autoencoder - GitHub - Jooong/Face-Aging-CAAE-Pytorch: Age Progression/Regression by Conditional Adversarial Autoencoder
github.com
https://github.com/ZZUTK/Face-Aging-CAAE
GitHub - ZZUTK/Face-Aging-CAAE: Age Progression/Regression by Conditional Adversarial Autoencoder
Age Progression/Regression by Conditional Adversarial Autoencoder - GitHub - ZZUTK/Face-Aging-CAAE: Age Progression/Regression by Conditional Adversarial Autoencoder
github.com
결과 :
저작권 상 사진 노출은 불가능.
150 에폭을 진행하여 결과물을 얻음.
블러 처리된 느낌이 강하게 있어 선명도가 떨어지는 이미지가 나옴
일반 AAE보다 훨씬 퀄리티가 좋고 사람 얼굴 같은 복원이 가능함
마스크 미착용 사진에 마스크를 씌운다던지 마스크 착용 사진에 하관을 생성한다던지 하는 작업은 불가능하고
오히려 어그러진 노이즈를 만들어냄
마스크를 쓰지 않은 얼굴에서 나이를 condition하여 생성하는 작업의 퀄리티가 좋음
나이를 변경할때 머리색이 검게 변한다던지 눈썹이 짙어진다던지 주름이 적어진다던지 하는 특징을 잘 살려냄
원본의 복원 상태가 가장 좋음
반성 :
1. 학습 속도를 채크해서 자원을 분배할 것. 제공된 V100서버에서는 다른 작업이 진행중이라 로컬의 3070 에서 학습을 진행했는데 생각보다 학습이 굉장히 오래걸렸음. 그래서 학습이 되는지 안되는지 빠른 판단이 불가능했고 학습 1회당 기본적으로 2시간은 기다려야했음. 결국 대회 마지막날까지 완벽한 학습이 되지 않아 제출해보지 못하고 끝남. 학습에 필요한 파라미터 수를 이용하여 필요한 GPU메모리, FLOPS 계산 가능. 계산된 값을 토대로 학습에 필요한 시간을 대략적으로 알 수 있음. 시간을 전략적으로 사용할 것.
2. 많은 공개자료를 통해 직관을 키울 것. 아직 퀄리티 좋은 generative model의 학습에대한 직관이 거의 없다는 것을 깨달음. 많은 공개자료를 직접 훈련해 보면서 직관을 늘릴 필요가 있음. StyleGAN을 통해서 훈련한 다른 조 캠퍼가 있었는데 이미 훈련된 모델을 통해 transfer learning을 진행하여 퀄리티를 확보하고 학습시간을 단축했다고 함.
'딥러닝 머신러닝 데이터 분석 > BoostCampAITech' 카테고리의 다른 글
| [CV] 0. Computer Vision OT & 1. Image Classification 1 & 2. Annotation data efficient learning (0) | 2021.09.07 |
|---|---|
| [P-Stage] 마스크 데이터 분류 대회 리포트 - 2 (0) | 2021.09.03 |
| [ BoostCamp ] Day-18 학습로그( PyTorch pretrained model ) (0) | 2021.08.20 |
| [ BoostCamp ] Day-17 학습로그( PyTorch의 구조 학습 ) (0) | 2021.08.20 |
| [ BoostCamp ] Day-16 학습로그( Pytorch Basic ) (0) | 2021.08.19 |

댓글